Lecture 9 - Pre-training LLMs: From Transformers to GPT
Welcome back!
Last time: Exam 1 on foundations and transformer architecture
Today: How do transformers become useful LLMs? The journey from toy models to GPT-5
Ice breaker
In a class, internship, project, or job, what's the largest ML model of any kind you've trained in terms of:
- Compute time
- Training set size
- Cloud compute cost
- Number of parameters
Agenda for today
- From toy transformers to LLMs: what changes at scale?
- Pre-training deep dive: data, objectives, infrastructure
- Scaling laws: bigger is better (with caveats)
- Activity: Design your training run
- Ethics spotlight: who pays the real costs?
Part 1: From Toy Transformers to LLMs
Recap: You've seen transformers
In Weeks 4-5, you learned:
- Attention mechanism (Q, K, V)
- Multi-head attention
- Transformer architecture (encoder + decoder blocks)
In labs (tomorrow!): You will implement attention and a tiny transformer
Typical lab-scale transformer:
- Vocab size: 5,000-10,000 tokens
- Embedding dimension: 128-256
- Number of layers: 2-4
- Number of heads: 4-8
- Total parameters: ~1-10 million
- Training time: minutes to hours on a single GPU
Transformer variants
Three flavors, depending on which attention mask you use:
- Encoder-only (BERT, RoBERTa):
- Bidirectional attention - each token sees the full sequence.
- Best for understanding tasks (classification, named entity recognition, question answering)
- Decoder-only (GPT, Claude, Gemini, Llama):
- Causal masking (the lower-triangular mask from L6)- each token sees only the past.
- Best for generation.
- Encoder-decoder (T5, BART, original transformer):
- Encoder reads input bidirectionally, decoder generates output autoregressively.
- Best for translation, summarization, anything mapping one sequence to another
Note: BERT's prediction head is training scaffolding and is discarded when fine-tuning. GPT's LM head is kept since generation is the task.
Modern LLMs are almost all decoder-only. Why?
Why decoder-only won
- The downside:
- Causal masking = each token sees only the past
- "bank" in "I went to the bank of the river" can't see "river" yet - genuinely ambiguous
- For generation, it doesn't matter:
- Answer tokens attend to the full prompt - "river" is visible at generation time
- Disambiguation happens when it needs to, not at encoding time
- Where encoder-only still wins:
- Embeddings and retrieval - RAG systems use BERT-style models for indexing
Scale: Production LLMs
GPT-3 (2020):
- 175 billion parameters
- ~34 days on 10,000 V100 GPUs
GPT-4 (2023, rumored):
- ~1.7 trillion parameters (mixture of experts)
- months of training, >$100 million
GPT-5 (August 2025):
- Parameters undisclosed, 272,000-token context window,
- ~$500 million per run (Wall Street Journal)
Big context doesn't mean perfect memory
GPT-5's 272,000-token context window. Does the model use it all equally?
Liu et al. (2023): "Lost in the Middle" - models attend much more to information at the start and end of context. Performance degrades on information buried in the middle.
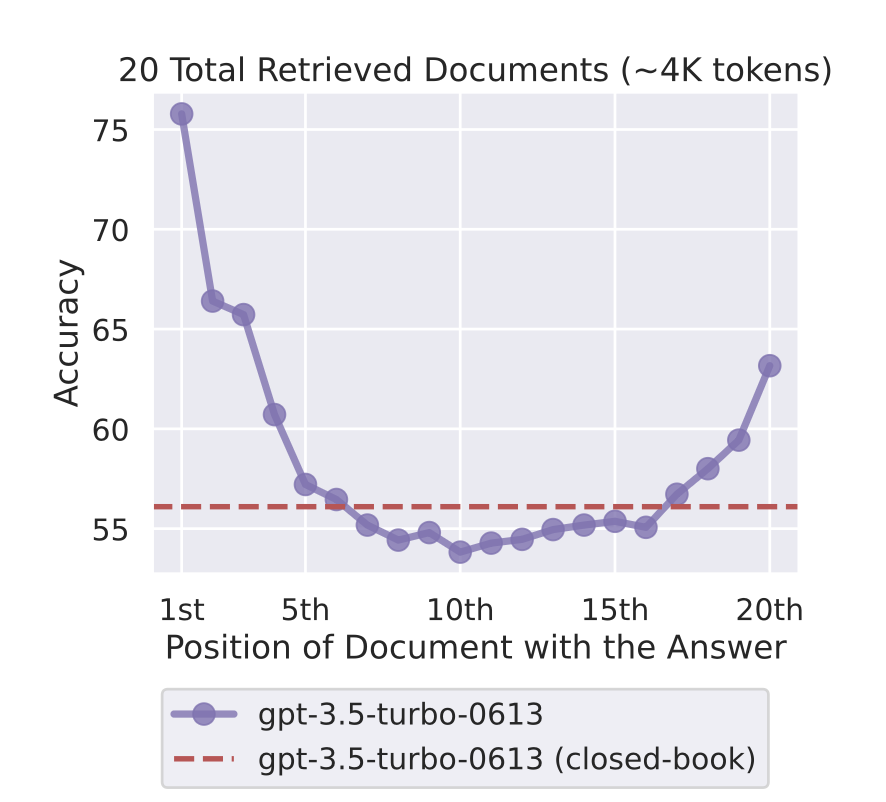
For practice: Put your most critical content first or last. This is one reason RAG can outperform stuffing everything into context. (More in Week 10.)
What changes at scale?
- Data: From thousands of examples to trillions of tokens
- Compute: From one GPU to thousands, from hours to months
- Infrastructure: Distributed training, checkpointing, monitoring
- Cost: From free (Colab) to millions of dollars
- Capabilities: Emergent abilities that don't appear at small scale
- Stakes: One bug can waste weeks and millions of dollars
Part 2: Pre-training Deep Dive
What is pre-training?
Pre-training = learning from raw text
- No labels, no human annotations
- Just predict: "What comes next?" (GPT) or "What's masked?" (BERT)
- Learn language patterns, facts, reasoning from observation
- Then fine-tune for specific tasks (next week's lecture!)
Why "pre-training"? The "pre" means before fine-tuning/post-training - it's still the main event (99%+ of the compute)
Training objectives
- GPT (causal LM):
- Predict the next token, left-to-right only
- Naturally generates next tokens - generation is "free"
- BERT (masked LM):
- Predict masked tokens using both sides of context (~15% masked)
- Sees full context - understanding and classification are "free"
What does the training signal look like?
Loss = cross-entropy over next-token predictions
At each position, predict from ~32K-100K BPE tokens.
Loss = . Lower is better.
Perplexity = - this is the standard metric you'll see in papers
- Perplexity 10: model is "as confused as if choosing uniformly among 10 options"
- Perplexity 1: perfect prediction
- GPT-3 achieves ~20 perplexity on standard benchmarks
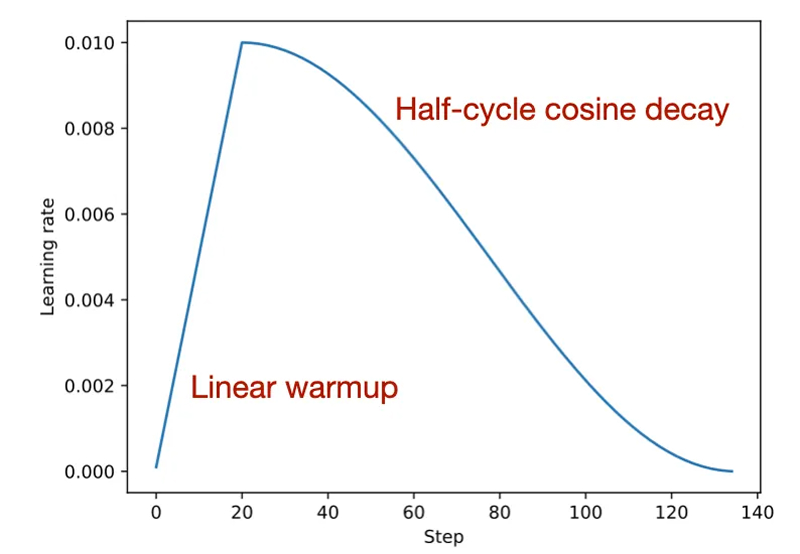
Learning rate schedule:
- Warmup for ~1K steps (avoid early instability), then cosine decay to near-zero
- Big updates early, fine adjustments late - standard for all modern LLMs
Where does training data come from?
Modern LLMs are trained on diverse text sources:
- Common Crawl: Web pages (petabytes of text)
- Books: Fiction and non-fiction (Books3 dataset, ~100k books)
- Wikipedia: High-quality encyclopedic content
- Code: GitHub repositories (for Codex, Copilot)
- Research papers, news articles, forums, social media...
Before we look at how it's done...
Quick discussion (2 min):
If you were building a training dataset from a raw scrape of the internet - what would you keep? What would you throw out? What percentage do you think actually makes it into the final training data?
Data curation: It's not just "download the internet"
Raw Common Crawl is full of garbage:
- Spam, ads, boilerplate text
- Duplicate content (same text repeated thousands of times)
- Low-quality text (typos, gibberish, machine-generated)
- Toxic content (hate speech, explicit material)
- Personal information (emails, phone numbers, addresses)
What raw web text actually looks like
A realistic sample (before cleaning):
Home | About | Services | Contact | Home | About | Services | Contact
BUY CHEAP WIDGETS ONLINE! Best widget prices 2019! Cheap widgets!
Click here click here click here click here click here
Copyright © 2019 All rights reserved Privacy Policy Terms Sitemap
Lorem ipsum dolor sit amet consectetur adipiscing elit sed do eiusmod
After cleaning (~2% survives):
Transformer models represent each token as a high-dimensional vector.
Self-attention allows the model to weigh the relevance of every other
token when producing a representation for each position in the sequence.
Most of the web looks like the top example - not bad writing, just no signal
Data cleaning pipeline
- Deduplication: Remove near-duplicate documents
- Quality filtering: Heuristics (word count, punctuation, ratio of letters to numbers)
- Toxicity filtering: Remove hate speech, explicit content
- PII removal: Scrub personal information
- Classifier-based filtering: Train a model to predict quality
GPT-3 result: ~45TB in, ~570GB out - over 98% filtered out
Who decides what's "quality"?
OpenAI's approach (WebText):
- Positive examples: text from URLs shared in Reddit posts with 3+ upvotes
- Positive examples: Wikipedia articles
- Negative examples: everything else from Common Crawl
What does "Reddit-approved" text bias toward?
- English content, Western topics, tech/finance/gaming
- Demographics: young, male, college-educated
- Writing styles that get upvotes (confident, punchy, sometimes glib)
Every quality signal encodes someone's judgment. This is where bias enters before any intentional decisions.
Curriculum learning
Not all data should be seen in random order
Idea (Bengio et al., 2009): Start with easier examples, gradually increase difficulty
Two mechanisms:
- Data ordering: Simple, clean text early; complex documents, code, math later
- Data mix scheduling: Change the proportion of each source over training
"Annealing":
- Near end of training: upweight highest-quality data (books, math, code)
- Why it matters: these are the final updates - nothing comes after to overwrite them
- The low learning rate means small, stable adjustments, so the annealing data steers the final resting point without instability
- LLaMA-3: final phase emphasized STEM and code to sharpen reasoning
Training infrastructure
Why can't you just use a bigger GPU?
175B params × 2 bytes (FP16) = ~350GB. An A100 has 80GB. The model doesn't fit.
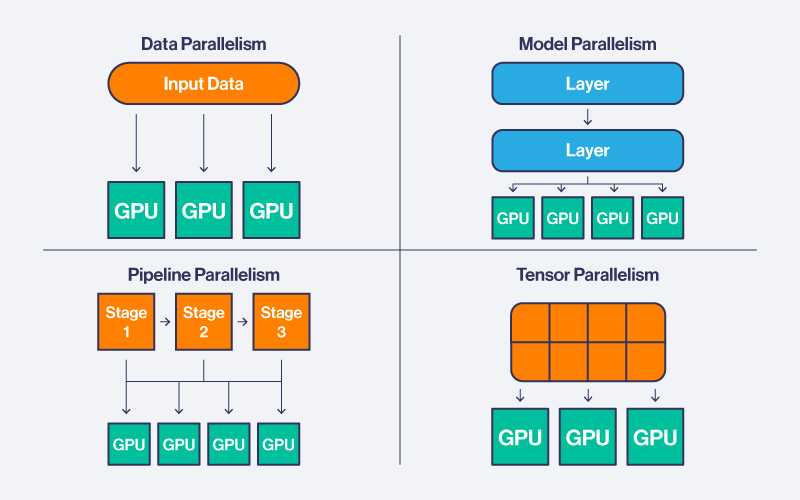
Distributed training across thousands of GPUs:
- Data parallelism: Each GPU holds a full model copy, processes different batches
- Model parallelism: Split layers across GPUs - GPU 1 runs layers 1-24, GPU 2 runs 25-48, etc.
- Pipeline parallelism: Different GPUs handle different stages of the forward pass
Training infrastructure hacks
- ZeRO (Zero Redundancy Optimizer):
- Adam tracks momentum + variance per weight - optimizer states add ~4x the weight memory
- Partitions weights + gradients + optimizer states across GPUs - each stores only 1/N
- Mixed precision (FP16/BF16):
- Forward/backward in 16-bit float (half the memory of FP32)
- Weight updates stay in FP32 for numerical stability
Checkpointing and monitoring
Training runs for weeks/months - things will go wrong
- Checkpointing: Save model state every N steps
- Monitoring: Track loss, gradients, activation statistics
- Debugging: If loss spikes or diverges, roll back to last good checkpoint
- Failures: Hardware failures, out-of-memory errors, network issues
This is unglamorous - but it's what makes it all possible.
Part 3: Scaling Laws
The scaling hypothesis
Observation: More compute + more data + bigger models = better performance
But how much better?
Empirical finding (Kaplan et al., 2020):
- Loss scales predictably with model size, dataset size, and compute
- Power law relationship: Loss ~ C^(-α) where C is compute
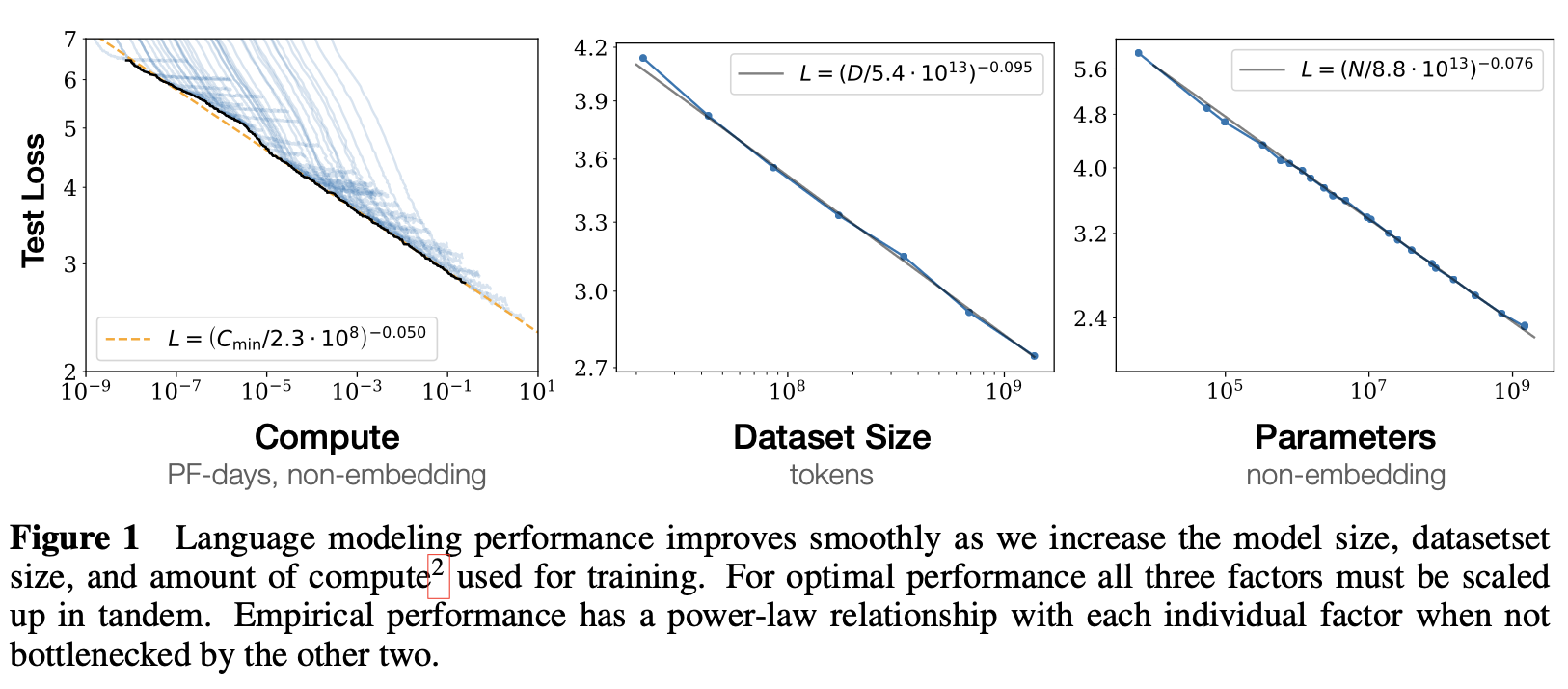
From the paper "Scaling Laws for Neural Language Models"
Kaplan scaling laws (2020)
Key findings:
- Model size matters most: Bigger models are more sample-efficient
- Data and compute trade off: You can get same performance with more data + smaller model, or less data + bigger model
- Smooth scaling: No discontinuities or surprises (at least in terms of loss)
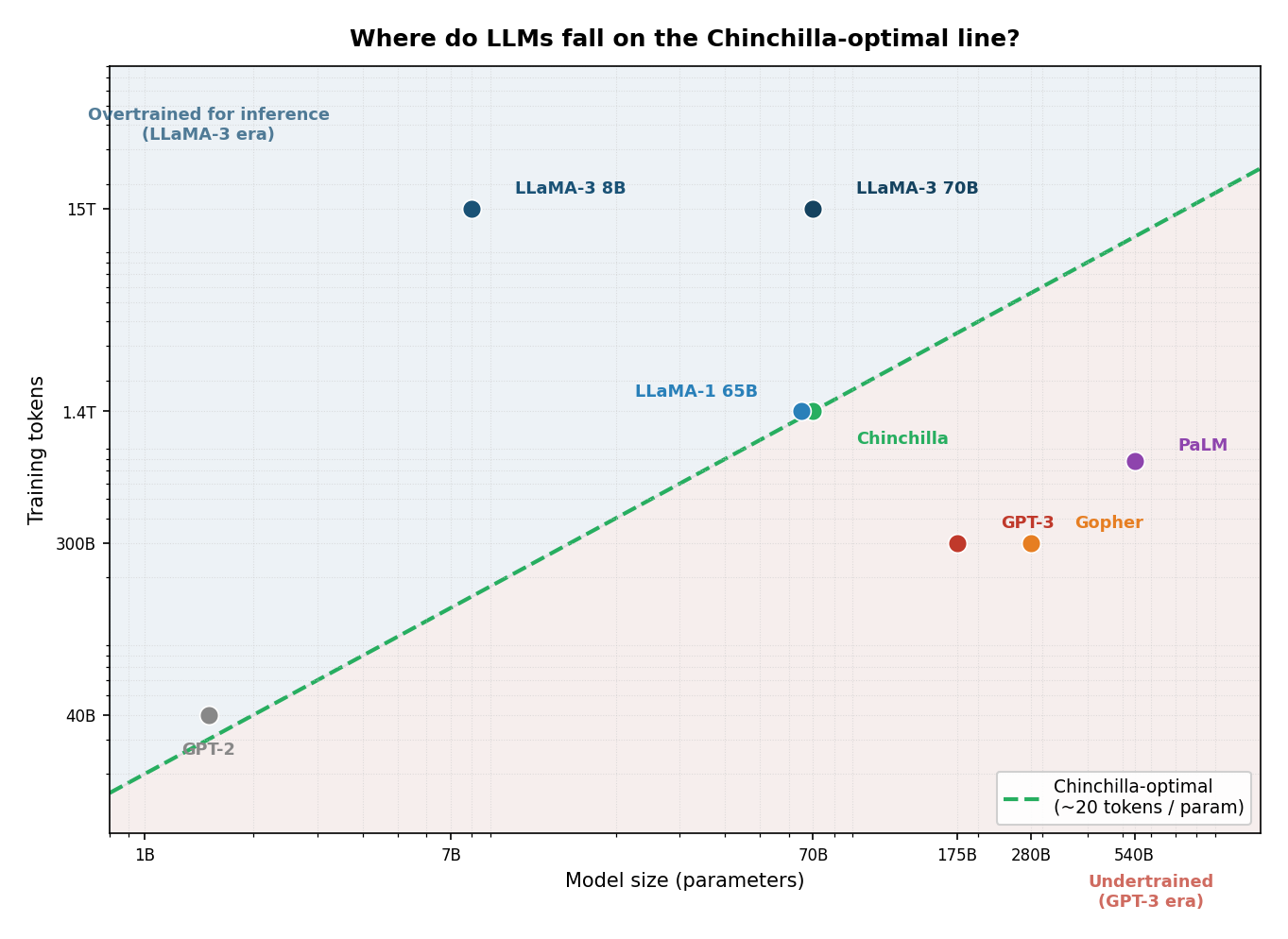
Chinchilla scaling laws (2022)
- Old wisdom (GPT-3 era): large models, modest data
- New wisdom (Chinchilla): balance model size AND data size for a fixed compute budget
- Proof: Chinchilla (70B params, 1.4T tokens) beats Gopher (280B params, 300B tokens) at same compute
- Implication: GPT-3 was undertrained - race shifted from "biggest model" to "best training recipe"
Why is there an optimal balance?
If you had 10x the compute budget, where should you spend it - model or data?
Loss from training a model with parameters on tokens:
- = irreducible loss. Even perfect prediction can't eliminate language's inherent entropy.
- = model-size term. More parameters, lower loss. Diminishing returns.
- = data-size term. More tokens, lower loss. Also diminishing returns.
Two knobs. Each attacks a different term.
IsoFLOP curves - how Chincilla was perfected
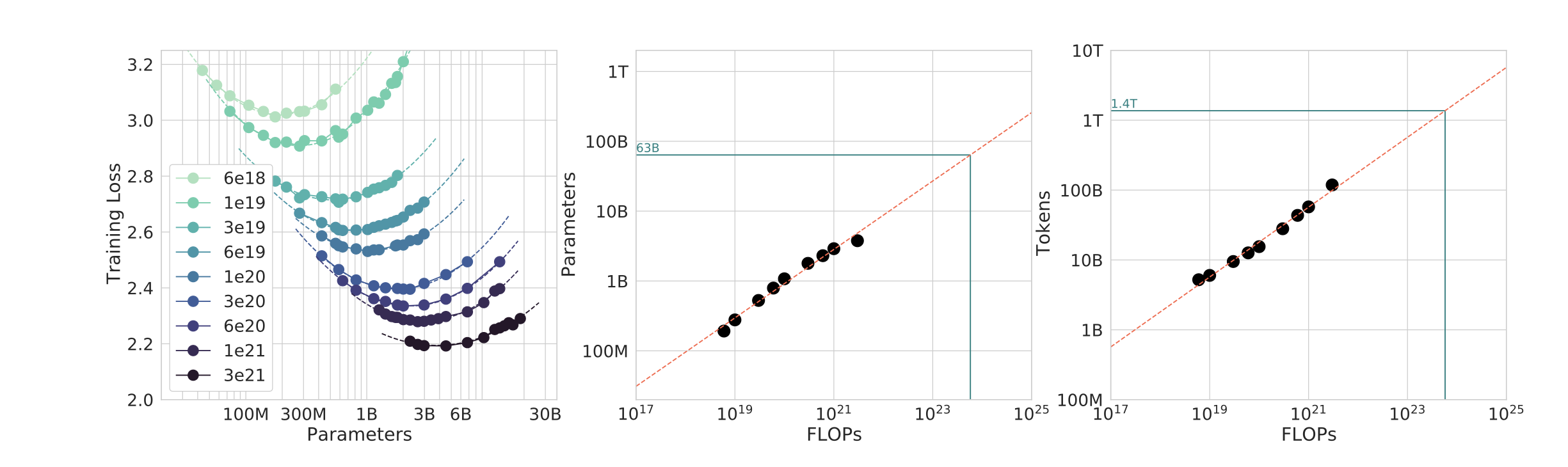
Where do major models fall relative to Chincilla?
The data wall
Scaling laws assume unlimited data. We're nearly out.
- Models have trained on essentially all publicly available text: Common Crawl, Wikipedia, books, code, forums
- The Chinchilla rule says a 7B model needs 140B tokens. GPT-4-scale models need trillions - we've used them.
- More compute doesn't help if there's no new data to train on
The proposed solution: synthetic data
- Use existing models to generate new training data
- LLaMA-3, Phi-3, and others already rely on this heavily
The question: Does synthetic data preserve quality? Or do errors and biases amplify?
- "Model collapse" (Shumailov et al., 2023): quality degrades when models train on their own outputs repeatedly - errors and biases compound across generations
Emergent abilities
Something unexpected: capabilities that suddenly appear at scale
- Small models can't do arithmetic, large models can
- Small models can't do few-shot learning, large models can
- Chain-of-thought reasoning emerges around 60B-100B parameters
- True phase transitions, or just crossing a usefulness threshold?
- Caveat: discrete (0/100%) metrics make smooth improvement look like sudden jumps
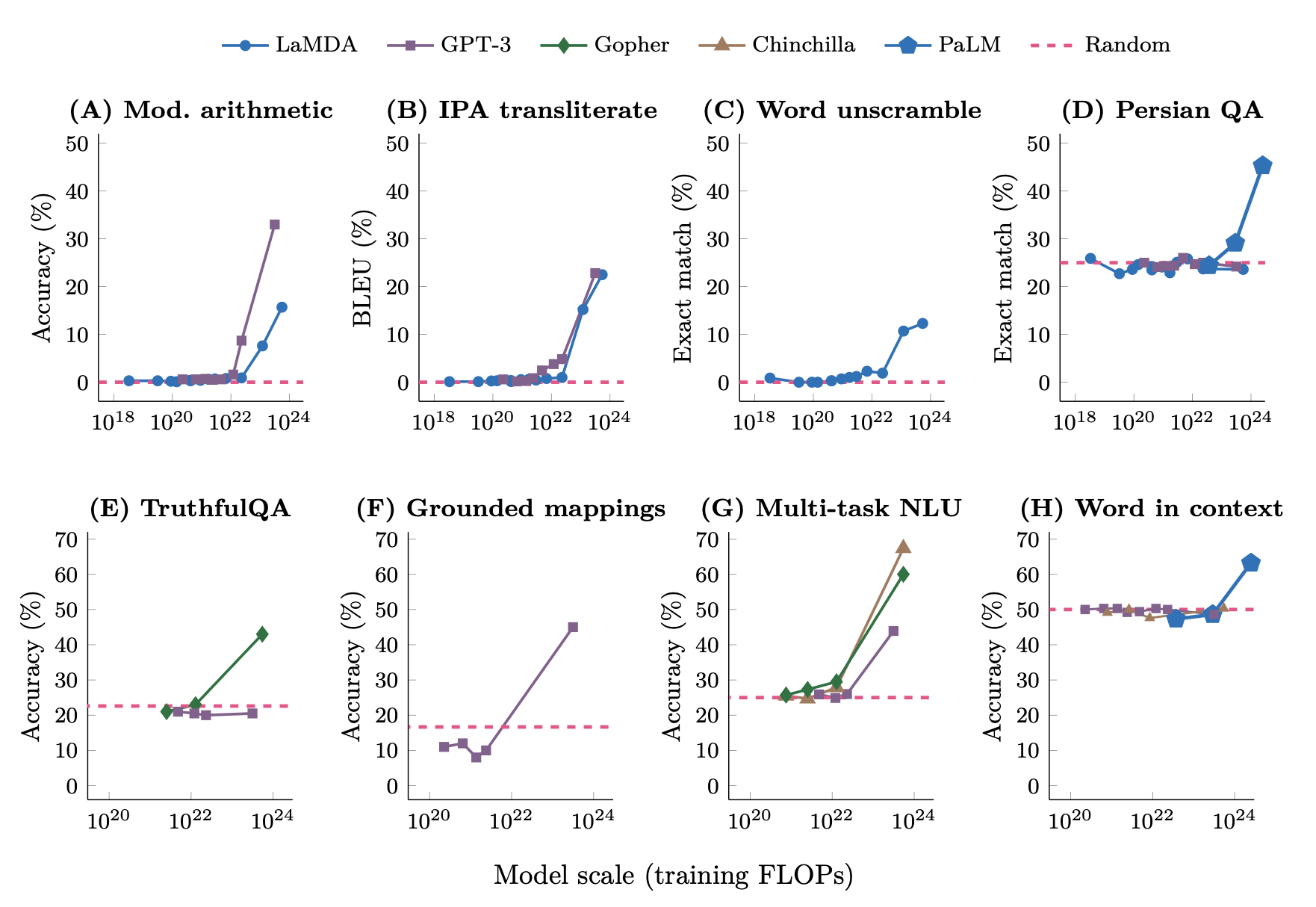
Wei et al. (2022), "Emergent Abilities of Large Language Models"
Wait - are emergent abilities real?
Schaeffer et al. (2023): "Are Emergent Abilities a Mirage?"
The finding: switch the metric, and the phase transitions largely disappear
- Discrete metric: "Did the model get this exactly right?" - 0% or 100%. Small model: 0%, large model: 80%, looks like a sudden jump.
- Continuous metric: "How many digits of the answer are correct?" shows smooth improvement across all model sizes. No jump.
The phase transition is in the metric, not the model
Why this matters for AI safety:
- If emergence is real: we might be blindsided by sudden dangerous capability jumps
- If it's a measurement artifact: scaling is more predictable than we thought
- The debate is unsettled, and it changes how you think about risk
Part 4: Activity - Design Your Training Run
Activity: Design your training run
The scenario: Your lab has $10 million in compute budget. Your goal: build a model that achieves a passing score on the LSAT - trained from scratch, no fine-tuning of existing models.
With a partner (5 min):
- Dataset: What text would you train on? Estimate how many tokens you could collect.
- Model size: Chinchilla rule: ~20 tokens per parameter. What size does your dataset imply?
- Compute check: Look up current H100 cloud pricing (~$2-4/hr per GPU on Lambda Labs or AWS). Does $10M cover your training run?
Be ready to share your numbers.
Activity debrief
What did people find? Token count, implied model size, estimated compute cost.
The twist: compute is not the bottleneck.
- High-quality legal text (court opinions, casebooks, LSAT prep) is probably 1-10 billion tokens.
- Chinchilla-optimal for 5B tokens: ~250M parameters.
- Training cost: roughly $10-50K. You have $9.95 million left over.
The bigger question: Would a 250M-parameter model trained from scratch on legal text outperform GPT-4 with a good system prompt? Probably not - which raises a question for Wednesday: what if you fine-tuned an existing model on that same legal corpus?
Who can afford to train LLMs?
At $5-100 million per training run:
- Big tech companies (OpenAI/Microsoft, Google, Meta, Anthropic)
- Well-funded startups (Cohere, Inflection, Mistral)
- Large research labs (DeepMind, Allen AI, EleutherAI with donations)
- Not: Most universities, small companies, researchers, or countries
This concentrates power: who trains the models decides what they can do, whose values they encode, and who gets access. Most researchers must use APIs from the same handful of companies.
Plot twist: DeepSeek-R1 (January 2025)
DeepSeek, a Chinese AI lab, released a frontier-quality model for ~$6 million
- Competitive with GPT-4 on reasoning and coding benchmarks
- US export controls blocked access to H100 GPUs - they used older H800s
- Constraint forced efficiency: distillation, RL without human labels, mixture-of-experts
- MoE: only a fraction of parameters activate per token - effective compute much lower than total param count
The caveats:
- $6M = compute only. Salaries, data, failed runs, and the cost of the teacher model they distilled from aren't included
- They had access to outputs from much more expensive models for distillation
- But even with all that: the efficiency gap with frontier US labs is real and significant
Does this change who can train LLMs? Or does it just change what "affordable" means?
DeepSeek: the deeper questions (skip if short on time)
- Distillation: DeepSeek trained on outputs from GPT-4 and Claude
- You can absorb an expensive model's knowledge without paying for it
- Raises questions about licensing, competitive moats, and who "owns" learned capabilities
- Chip restrictions: Did export controls fail? Or create just enough friction?
- Being denied H100s forced efficiency innovations that might not have happened otherwise
- The bottleneck may shift from hardware to algorithmic know-how - harder to restrict
Part 5: Ethics Spotlight
The real costs of scale
We've covered environmental and data ethics before. Quick recap:
- Carbon: GPT-3 training ~550 tons CO₂ (one-time). Inference at scale is the ongoing cost.
- Copyright: Scraped without permission. Lawsuits from authors (Sarah Silverman), artists, programmers.
- Bias: Encoded in data choices before any intentional decisions - starting with Reddit upvotes.
The part we haven't talked about: where does the infrastructure go?
Case study: New Brunswick, NJ (February 2026)
A community just stopped an AI data center:
- Proposed: 27,000 sq ft facility at 100 Jersey Avenue in New Brunswick, NJ
- City Council voted unanimously to cancel it on Feb 19, 2026
- Concerns: electricity costs, water consumption, noise, neighborhood impact
- "We don't want these kinds of centers that's going to take resources from the community." - Bruce Morgan, president of the New Brunswick NAACP

- Site will instead host 600 apartments (10% affordable housing), startup warehouse space, and a public park
- Context: NJ residents have seen significant electric bill increases partly due to existing data center operations
- Rutgers University is in New Brunswick - students were among those who packed City Hall
Discussion: Is there a sustainable path forward?
- Should we slow down LLM scaling given environmental costs?
- How can we make LLM training more accessible and democratic?
- What regulations (if any) should exist for training data sourcing?
Wrap-up: Key takeaways
- Scale changes everything: LLMs aren't just bigger models, they're different engineering challenges
- Training is expensive: $5-100 million, weeks to months, thousands of GPUs
- Scaling laws are predictable: More compute + more data = better performance (with diminishing returns)
- Chinchilla insight: Balance model size and data size for compute-optimal training
- Ethics matter: Environmental impact, data sourcing, concentration of power
Looking ahead
Next lecture (Wednesday):
- Post-training: What happens after pre-training?
- Instruction tuning: Making models follow instructions
- RLHF: Reinforcement learning from human feedback
- Alignment: Whose values? How do we ensure safety?
Due Wednesday:
- Portfolio piece peer reviews
- You can expect exam grades back
Due Friday:
- Reflections
- Course survey
- Participation self-assessment
- I'll ask you to decide about oral re-exams