Lecture 6 - Attention Mechanisms
Welcome back!
Last time: Encoder-decoder models and word embeddings - how we represent meaning and handle sequences
Today: The mechanism that revolutionized NLP - attention
Why this matters: Attention solves the bottleneck problem and enables transformers
Ice breaker

What do you see in this picture? Can you tell what's going on?
- Visual saccades
- The classic test
Agenda for today
- Quick recap: the bottleneck problem
- Attention intuition: Query, Key, Value
- The math: scaled dot-product attention
- Board work: computing attention step by step
- Self-attention: a sequence attending to itself
- Multi-head attention: multiple perspectives
- Masked attention: padding and causal masks
Part 1: Recap - The Bottleneck Problem
Remember encoder-decoder models?
From Lecture 5:
Input sequence -> Encoder -> Fixed-size context vector -> Decoder -> Output sequence
Example task: Translate English to French
"The snow closed the campus" -> [encoder] -> c -> [decoder] -> "La neige a fermé le campus"
The bottleneck problem
Challenge: Compress entire input sequence into one fixed-size vector
Long inputs lose information:
Short sentence (5 words) -> c (256 dims) -> works ok
Long paragraph (100 words) -> c (256 dims) -> loses details!
It's like summarizing a novel in one sentence - you lose crucial details
Try it: 5-word summary
Pick your favorite book or movie. Summarize the entire story in exactly 5 words.
Share with your neighbor, can they guess what it is?
Hard, right? That's the bottleneck problem. Now imagine compressing a 100-word paragraph into a 256-dimensional vector.
What if we could look back?
Intuition: When generating each output word, look at all the input words and focus on the most relevant ones
Example: Translating "I got cash from the bank on the way home"
When generating "banque" (bank), the model attends to both "bank" and "cash" - it needs the context to know this is a financial bank, not a riverbank
This is attention!
Attention: high-level idea
Instead of a single context vector, the decoder gets a dynamic context for each output
Each decoder step:
- Look at all encoder hidden states (roughly, token embeddings)
- Decide which ones are most relevant
- Create a weighted combination
- Use that as context for this step
Result: The model can focus on different parts of the input for different outputs
Part 2: Query, Key, Value - The Attention Intuition
Three roles in attention
Attention uses three different representations of the same data:
Query (Q): "What am I looking for?"
Key (K): "What do I contain?"
Value (V): "What do I actually output?"
Metaphor: Googling your symptoms
You wake up with a headache and blurry vision. Naturally, you do the responsible thing and consult Dr. Google.
Your search: "headache blurry vision" - This is Q
Page titles and descriptions: What each result claims to be about - These are Ks
The actual articles: The content you read when you click - These are Vs
Metaphor: Googling your symptoms
- Type in your symptoms (Q)
- Skim titles and descriptions for matches (compare Q to all Ks)
- Click into the most relevant results and read them (retrieve their Vs)
- Combine what you read into your (probably wrong) self-diagnosis
This is exactly how attention works!
Attention beyond translation
Translation is our running example, but attention is everywhere:
Document summarization: When generating each summary word, attend to the most relevant sentences in the source document
Image captioning: When generating "dog," attend to the dog region of the image; when generating "frisbee," shift attention to the frisbee
Question answering: Given a question about a passage, attend to the sentences most likely to contain the answer
The same Q, K, V mechanism works across all these tasks!
Q, K, V in the decoder attending to encoder
Example: Translating "The snow closed" -> "La neige a ___"
Decoder is generating the next French word
Query (Q): Current decoder state (Q = "what's the next word in my translation after 'La neige a'")
Keys (K): All encoder hidden states (titles/descriptions for "The", "snow", and "closed")
Values (V): The same encoder hidden states (full content of "The", "snow", and "closed")
Process:
- Compare Q to all Ks -> get relevance scores
- Use scores to weight the Vs
- Output weighted combination of Vs
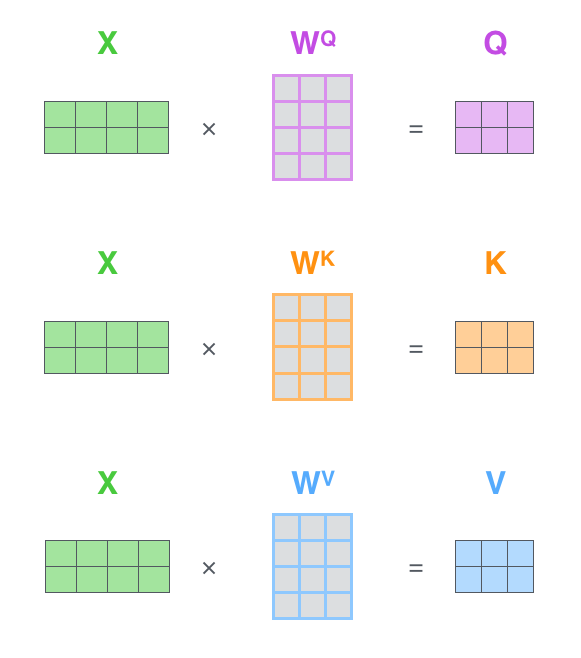
Why K and V are separate
Question: If K and V both come from encoder hidden states, why distinguish them?
Answer: We transform them differently!
In practice:
= Optimized for matching
= Optimized for content
W_K and W_V are learned projection matrices (sometimes called weight matrices)
Keys learn to be good for comparison (which inputs match this query?)
Values learn to be good for output (what information to pass forward?)
Part 3: The Math - Scaled Dot-Product Attention
The attention formula
Given: Queries (Q), Keys (K), Values (V)
Compute:
Let's break this down step by step
Step 1: Compute similarity scores
What this does: Dot product between query and all keys
Intuition: "How well does my query match each key?"
Output: Similarity scores (higher = more relevant)
Dimensions:
: - one query
: - n keys (one per input token)
: - one score per input token
Step 2: Scale by sqrt(d_k)
Why scale? Dot products get large when dimensionality () is high
Problem with large scores: Softmax saturates (pushes probabilities toward 0 or 1)
Solution: Divide by to keep scores in a reasonable range
Step 3: Softmax
What softmax does: Converts scores to probabilities (sum to 1)
Input: Raw similarity scores [3.2, 1.1, 5.8]
Output: Attention weights [0.15, 0.05, 0.80]
Interpretation: "Focus 80% on token 3, 15% on token 1, 5% on token 2"
Step 4: Weighted sum of values
Finally: Multiply attention weights by values
This creates a weighted combination of the input values
Example:
Attention weights: [0.15, 0.05, 0.80]
Values:
Output: $0.15 \times v_1 + 0.05 \times v_2 + 0.80 \times v_3$
The output focuses on the most relevant values!
Putting it all together
$Q \cdot K^T\sqrt{d_k}$ 3. Normalize: softmax -> probabilities 4. Weighted sum: multiply by V
Result: Context vector that focuses on relevant input tokens
Computational cost: $O(n^2)QK^T(n \times n)n^2$ similarity calculations!
Implications:
- Short sequences (100 tokens): 10,000 comparisons - fast
- Long sequences (10,000 tokens): 100,000,000 comparisons - slow!
This is why: Long documents are challenging, and researchers work on "efficient attention" variants
Quick check: vibe-coding and context limits
How's the vibe-coding going? Have you encountered:
- Your conversation gets long,
- the model starts "forgetting" earlier context
- and eventually you hit a structural limit on context length
We know forgetting happened with RNNs - why is it still happening with attention?
Quick check: Do you understand the formula?
Turn to your neighbor (2 min):
In your own words, explain what each step accomplishes:
- QK^T - what does this compute?
- Softmax - why do we need this?
- Multiply by V - what's the result?
Part 4: "Board" (Screen) Work
Let's calculate attention by hand
Scenario: Translating "snow closed campus"
We have 3 input tokens (words), and we're generating an output
Simplified example with d_k = 4
(Real models use d_k = 64 or larger, but 4 is enough to see the pattern)
Step 1: Set up matrices
Query (what we're looking for):
Q = [1, 0, 1, 2]
Keys (what each input contains):
K = [[2, 1, 0, 1], ← "snow"
[0, 2, 1, 0], ← "closed"
[2, 0, 1, 2]] ← "campus"
Values (what we output):
V = [[1, 0, 1, 2], ← "snow"
[0, 1, 2, 0], ← "closed"
[2, 1, 0, 1]] ← "campus"
Step 2: Compute $QK^TQ \cdot K^TQ = [1, 0, 1, 2]Q \cdot [2, 1, 0, 1] = 1\times2 + 0\times1 + 1\times0 + 2\times1 =Q \cdot [0, 2, 1, 0] = 1\times0 + 0\times2 + 1\times1 + 2\times0 =Q \cdot [2, 0, 1, 2] = 1\times2 + 0\times0 + 1\times1 + 2\times2 =$ 7 ← similarity with "campus"
Scores: [4, 1, 7]
Observation: "campus" has highest similarity to our query!
Step 3: Scale by $\sqrt{d_k}d_k = 4\sqrt{d_k} =$ 2
Scaled scores: [4/2, 1/2, 7/2] = [2, 0.5, 3.5]
Step 4: Apply softmax
Scaled scores: [2, 0.5, 3.5]
Softmax: Convert to probabilities (approximate!)
$\text{softmax}([2, 0.5, 3.5]) \approx$ [0.18, 0.04, 0.78]
Check: 0.18 + 0.04 + 0.78 = 1.0
Interpretation:
- Focus 78% on "campus"
- Focus 18% on "snow"
- Focus 4% on "closed"
Step 5: Weighted sum of values
Attention weights: [0.18, 0.04, 0.78]
Values:
- $V_1V_2V_3= 0.18 \times [1, 0, 1, 2] + 0.04 \times [0, 1, 2, 0] + 0.78 \times [2, 1, 0, 1]\approx [0.18, 0, 0.18, 0.36] + [0, 0.04, 0.08, 0] + [1.56, 0.78, 0, 0.78]\approx$ [1.74, 0.82, 0.26, 1.14]
This is our context vector - a weighted combination focused on "campus"
What did we just do?
Started with: Query asking "what am I looking for?"
Compared to: Keys for each input token
Found: "campus" was most relevant (similarity = 7, then scaled to 3.5)
Retrieved: Weighted combination of values, focused 78% on "campus"
Result: A context vector that emphasizes "campus", the most relevant input
This is attention!
Attention Variants
Part 5: Self-Attention
From cross-attention to self-attention
So far, we've seen the decoder attending to the encoder (cross-attention).
But what if Q, K, and V all come from the same sequence?
Self-attention: Each word in a sentence attends to all other words (including itself)
Why? To build better representations by capturing relationships within the sequence
Self-attention in action
Input sentence: "The animal didn't cross the street because it was too tired"
Question: What does "it" refer to?
Self-attention for the word "it":
- Query: "it" embedding
- Keys/Values: All word embeddings in the sentence
Results:
- High attention to "animal" (that's what "it" refers to!)
- Low attention to "street"
The Great Jay Alammar
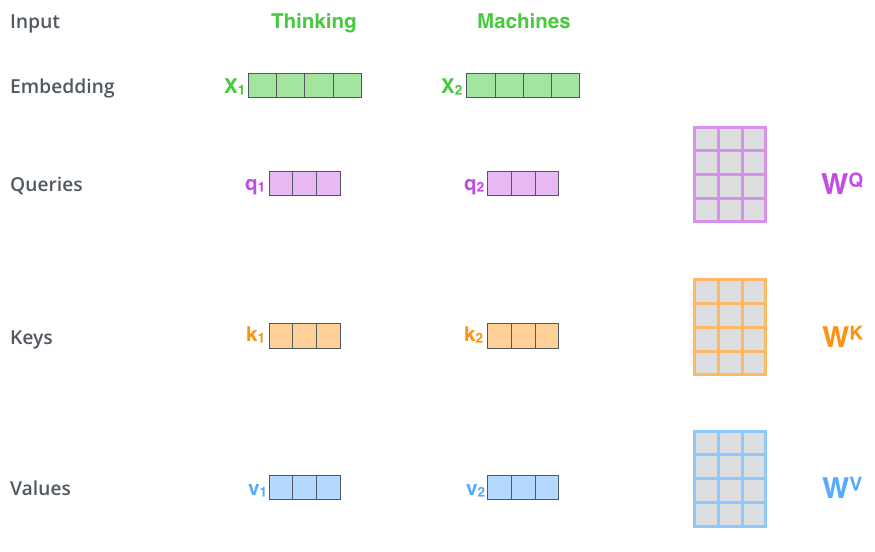
The process
For each word in the sequence:
-
Create Q, K, V from that word's embedding (using learned projection matrices W_Q, W_K, W_V)
-
Compare Q to all K's (including itself) -> attention weights
-
Weighted sum of all V's -> contextualized representation
Do this for ALL words simultaneously! (this is why transformers are parallelizable, unlike RNNs)
Result: Every word gets a new representation that incorporates information from the whole sequence
The Great Jay Alammar II
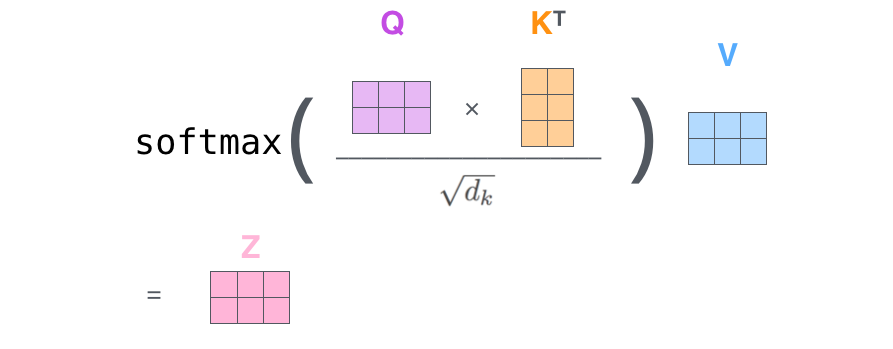
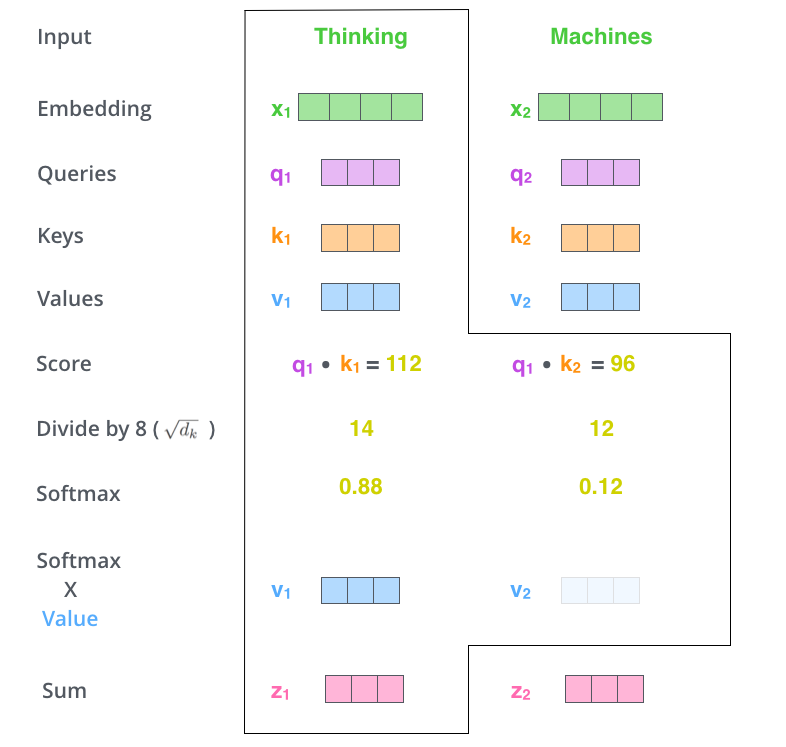
Cross-attention vs self-attention
| Cross-attention | Self-attention | |
|---|---|---|
| Q comes from | Decoder | Same sequence |
| K, V come from | Encoder | Same sequence |
| Purpose | "What input is relevant to what I'm generating?" | "How do words in this sequence relate to each other?" |
| Formula | $\text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V\text{softmax}\left(\frac{QK^T}{\sqrt{d_k}}\right) V$ |
The math is identical. Only the source of Q, K, V changes.
Live demo: BertViz
Before we calculate by hand, let's see what attention actually looks like in a real model.
Demo: scripts/bertviz_demo.ipynb

Was this insightful at all? You might take sides between the papers:
- "Attention is not explanation" (Jain and Wallace, 2019)
- "Attention is not not explanation" (Wiegreffe and Pinter, 2019)
Part 6: Multi-Head Attention
One head isn't enough
In "The snow closed the campus":
- Syntactic: "snow" is the subject of "closed"
- Semantic: "snow" and "campus" (weather event affecting a place)
- Positional: "snow" is near "The"
Problem: A single attention mechanism tries to capture all these relationships at once
Solution: Run multiple attention "heads" in parallel - each one learns to focus on different things
Multi-head attention: The idea
Instead of one set of Q, K, V:
Run h different attention mechanisms in parallel (typically h = 8 or 16)
Each head:
- Has its own W_Q, W_K, W_V projection matrices
- Learns to focus on different aspects
- Produces its own output
Finally: Concatenate all head outputs and project
Multi-head attention formula
For each head i:
$W_Od_k = d_v = 64$, total model dimension = 512
The Great Jay Alammar III
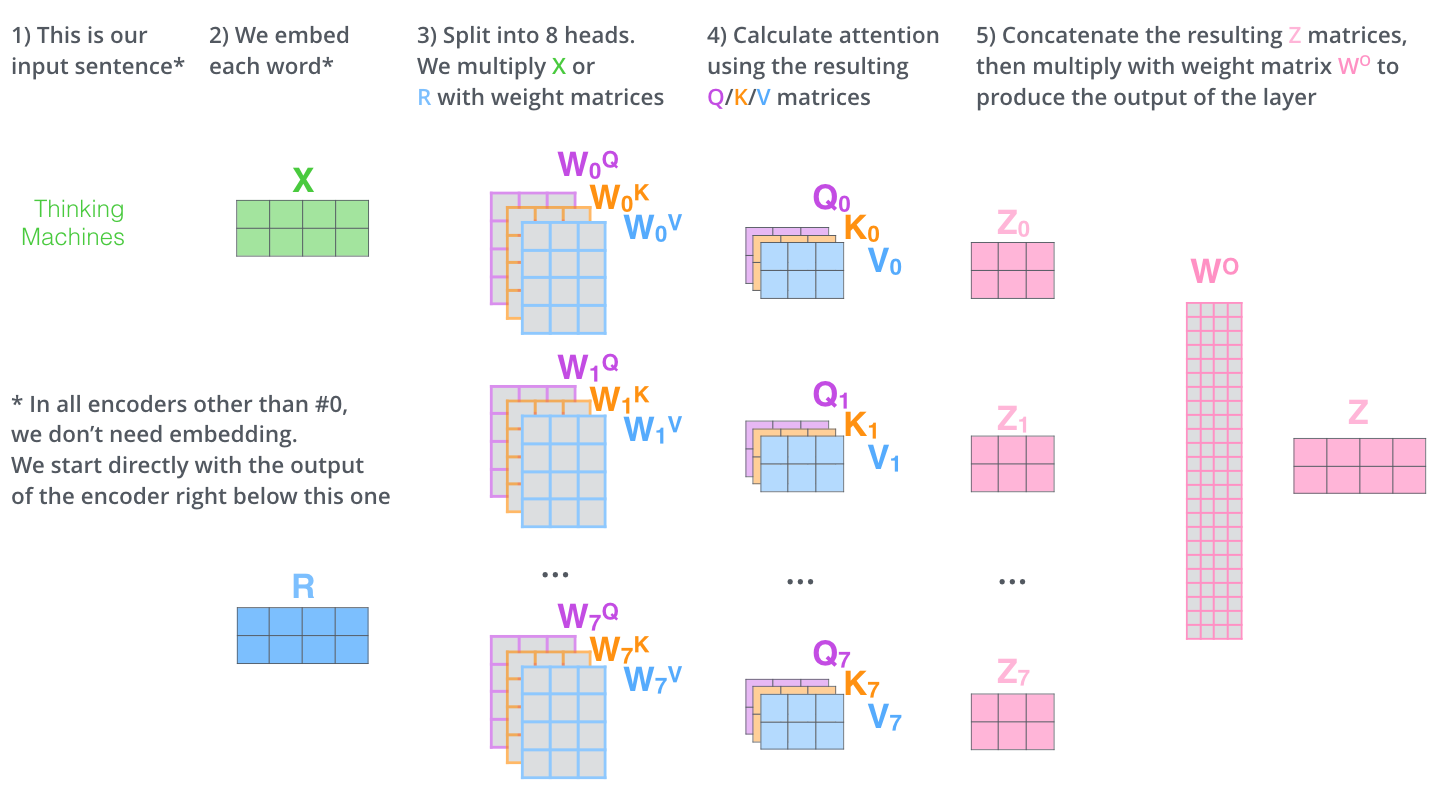
If you had 8 attention heads in this class...
What would each one attend to?
- Head 1: The slides
- Head 2: What the professor is saying
- Head 3: Whether it's almost 1:35
- Head 4: ?
- Head 5: ?
- Head 6: ?
- Head 7: ?
- Head 8: ?
The point: Each head specializes. No single head can capture everything, that's why we need multiple.
Stepping back
You now understand the core mechanism behind every modern LLM.
The attention formula (cross-attention, self-attention, same math) is what powers ChatGPT, Claude, BERT, and every transformer.
Multi-head attention just runs it multiple times in parallel for richer representations.
Question if we have time: How similar is this to how our brains work?
Part 7: Masked Attention
Masking Demystified
Why do we need masking? Two reasons:
- Padding: Batches have different sequence lengths
- Causal attention: Decoders can't look at future tokens
Padding mask
Problem: Batching sequences of different lengths
Batch:
Sentence 1: "The cat sat on the mat" (6 tokens)
Sentence 2: "I love NLP" (3 tokens)
Solution: Pad shorter sequence
Sentence 1: [The, cat, sat, on, the, mat]
Sentence 2: [I, love, NLP, PAD, PAD, PAD]
But we don't want attention to [PAD] tokens!
Padding mask: how it works
Create mask: 1 = real token, 0 = padding
Sentence 2: [I, love, NLP, PAD, PAD, PAD]
Mask: [1, 1, 1, 0, 0, 0 ]
During attention: Set masked positions to -∞
Before mask: QK^T = [2.1, 1.5, 3.2, 0.8, 0.5, 0.7]
After mask: [2.1, 1.5, 3.2, -∞, -∞, -∞ ]
After softmax: [0.3, 0.2, 0.5, 0.0, 0.0, 0.0]
Result: Padding gets zero attention weight.
Causal mask (for decoders/generation)
Problem: During training, the decoder can't peek at future tokens
Solution: Lower triangular mask - each position attends only to itself and earlier positions
pos 0 pos 1 pos 2 pos 3
pos 0 [ 1 0 0 0 ] "The"
pos 1 [ 1 1 0 0 ] "cat"
pos 2 [ 1 1 1 0 ] "sat"
pos 3 [ 1 1 1 1 ] "on"
Why? When generating "cat", the model has only seen "The". The mask enforces this at training time too.
Extra Discussion: moltbook
In the last few minutes... what do you think?
Project idea: scraping/analyzing this or writing your own bot to join them?
What we learned today
Attention solves the bottleneck problem - dynamic context instead of one fixed vector
Q, K, V framework: Query what you want, match against Keys, retrieve Values
Self-attention: The same mechanism, but a sequence attends to itself
Multi-head attention: Multiple perspectives in parallel
Masked attention: Two flavors - padding masks (ignore [PAD] tokens) and causal masks (can't peek at future)
Next time: The full transformer architecture
Highly recommended reading: The Illustrated Transformer by Jay Alammar
Lab reminder: Lab/reflections for week 4 due Friday
Tuesday: Positional encoding + encoder/decoder blocks + the complete picture