Lecture 5 - Sequence Models & Word Embeddings
Welcome back!
Last time: Tokenization - how text becomes pieces a model can process
Today: How those pieces get meaning - word embeddings and sequence models
Why this matters: These are the building blocks of every LLM
Ice breaker: Personal Corpus
(See Poll Everywhere)
Connecting the pieces
Lecture 2: Classical NLP (BoW, TF-IDF, n-grams) - count words
Lecture 3: Neural networks - the learning machinery
Lecture 4: Tokenization - break text into pieces
Today: Learn representations that capture meaning
Spoiler: LLMs are basically this idea at massive scale.
Agenda for today
- From counting to meaning: the distributional hypothesis
- Encoder-decoder framework for sequence tasks
- Word embeddings: Word2Vec and how neural networks learn meaning
- Properties of Embeddings
- Ethics: Bias in embeddings
- Quick intro to RNNs (and why transformers replaced them)
Part 1: The Distributional Hypothesis
The problem with counting
Remember n-grams from Lecture 2?
Training text: "I love NLP. I love machine learning."
Bigram model learns: I -> love, love -> (NLP or machine)
But what if we see: "I adore NLP"?
The model has no idea that "adore" and "love" are similar!
We need a representation that captures semantic similarity
The insight: distributional hypothesis
"You shall know a word by the company it keeps"
- J.R. Firth, 1957
Intuition: Words that appear in similar contexts have similar meanings
This is the foundation of how LLMs work.
For more theories, go down a rabbit hole on "semiotics"
Think about these sentences
"The cat sat on the mat"
"The dog sat on the mat"
"The automobile sat on the mat" (weird!)
Question: What other contexts do "cat" and "dog" share?
From contexts to vectors
Idea: Represent each word as a vector based on the contexts where it appears
Words in similar contexts lead to similar vectors
Example (simplified):
- "cat" -> [0.8 near "sat", 0.9 near "mat", 0.7 near "pet", ...]
- "dog" -> [0.9 near "sat", 0.8 near "mat", 0.9 near "pet", ...]
- "automobile" -> [0.1 near "sat", 0.0 near "mat", 0.0 near "pet", ...]
cat and dog vectors are close together in high-dimensional space!
Similarity voting - poll everywhere
Which word is MOST similar to "cat"?
A) dog B) car C) meow D) kitten
Round 2: Which is most similar to "Taylor Swift"?
A) Beyoncé B) Taylor Smith C) Travis Kelce D) 1989
Round 3: Which is most similar to "bank"?
A) river B) money C) rob D) save
What would a computer answer?
Part 2: Encoder-Decoder Framework
From single words to sequences
Word embeddings solve: Representing individual words as vectors
But many NLP tasks need: Processing and generating sequences
Machine translation: "I love NLP" -> "J'adore le NLP"
Summarization: Long article -> short summary
Question answering: Question + context -> answer
We need architectures for sequence-to-sequence tasks
The encoder-decoder architecture
High-level idea:
Encoder: Read the input sequence, build a representation
Decoder: Generate the output sequence using that representation
Example (translation):
- Encoder reads English: "I love NLP"
- Encoder outputs: [0.134, 0.841, ... , 0.529]
- Decoder uses that vector to generate French: "J'adore le NLP"
This framework is still how modern LLMs work:
- GPT, Claude, LLaMA: Decoder-only (generate text from a prompt)
- BERT: Encoder-only (understand text, don't generate)
- T5, translation models: Full encoder-decoder
Real-world impact: Google Translate (2016)
In 2016, Google switched from phrase-based translation to a neural encoder-decoder model.
Translation quality improved more in that single jump than in the previous 10 years combined.
Google released a great paper, "Google's Neural Machine Translation System: Bridging the Gap between Human and Machine Translation" if you want to learn more!
Encoder-decoder diagram
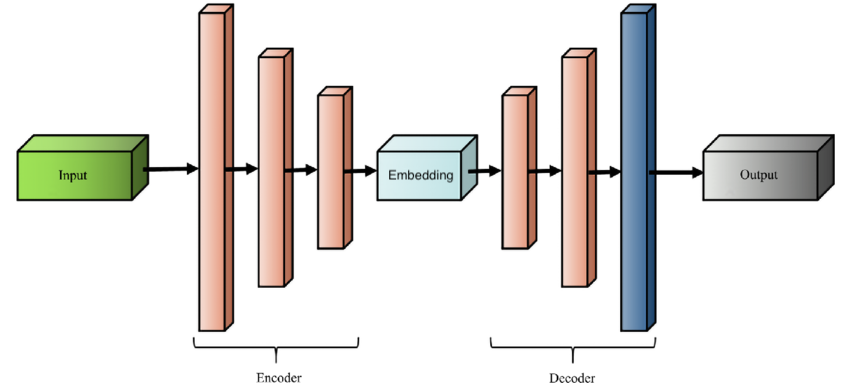
The context vector is the bottleneck!
This pattern is everywhere
Encoder-decoder isn't just for language, it's any time you compress information through a bottleneck and reconstruct on the other side.
| Domain | Encoder | Bottleneck | Decoder |
|---|---|---|---|
| Translation | Read English sentence | Context vector | Generate French sentence |
| Audio streaming | Raw audio waveform | Compressed bitstream | Reconstructed audio |
| Image compression | Full-resolution photo | Small image file | Reconstructed image |
| Biology | Original genetic sequence | Embedding space | Similar sequences functionally (VAE) |
The key trade-off is always the same: How small can you make the middle representation while still reconstructing something useful?
- Stable Diffusion (that's the "latent" in Latent Diffusion)
- Meta's EnCodec, Google's SoundStream
The bottleneck problem
Challenge: Compress an entire sentence into a single fixed-size vector
Short sentences: "Hi" -> 1 vector (okay)
Long sentences: "The quick brown fox jumps over the lazy dog" -> 1 vector (hard)
Very long: "In the beginning was the Word, and the Word was with God..." -> 1 vector (impossible)
The fixed-size vector becomes a bottleneck for long sequences
But what if we just... didn't compress?
Thought experiment: What if the decoder could look at ALL the word vectors' states, not just a single combined one?
Instead of: Input -> Encoder -> one vector -> Decoder -> Output
What about: Input -> Encoder -> all words available -> Decoder picks what it needs -> Output
This is exactly what attention does. Wednesday's topic!
Part 3: Word2Vec - Learning Embeddings with Neural Networks
From framework to technique
We have a framework: encoder builds a representation, decoder uses it. But how do we actually learn those word representations?
Word2Vec (Mikolov et al., 2013): Train a neural network on a dead-simple task: given a word, predict its neighbors. The representations it learns along the way turn out to capture meaning.
Skip-gram: The training task
- Training sentence: "The cat sat on the mat"
- Center word: "sat"
- Context window (size 2): the 2 words on each side
- Training pairs generated: (sat, cat), (sat, on), (sat, the), (sat, the)
The cat [sat] on the mat
↑ ↑ center ↑ ↑
context context context context
Each pair is a separate training example. Slide the window across billions of sentences and you get billions of training pairs.
Window size is a hyperparameter, typically 5-10.
- Larger windows capture semantic/topical similarity ("dog" and "cat" both appear near "pet")
- Smaller windows capture syntactic similarity ("dog" and "cat" both follow "the")
Skip-gram: The training data
What does the training set actually look like? Each center word paired with each context word is one training example: input x, target y.
"The cat sat on the mat", window = 2:
| Input (x) | Target (y) |
|---|---|
| The | cat |
| The | sat |
| cat | The |
| cat | sat |
| cat | on |
| sat | The |
| sat | cat |
| sat | on |
| sat | the |
| on | cat |
| on | sat |
| on | the |
| on | mat |
| the | sat |
| the | on |
| the | mat |
| mat | on |
| mat | the |
18 training pairs from a single 6-word sentence. The network sees each row independently: "given this input word (as a one-hot vector), try to predict this target word." Scale to billions of sentences and you get billions of training pairs.
Skip-gram: The architecture
This is a mini encoder-decoder:
Encoder (embedding layer): One-hot vector for "sat" (size 50,000) × weight matrix W_embed (50,000 × 300) = word vector (size 300)
This is just a lookup - multiplying a one-hot vector by a matrix pulls out one row.
Decoder (context layer): Word vector (size 300) × weight matrix W_context (300 × 50,000), then softmax to get probability for each word in the vocabulary
Training: For each pair (sat, cat), did the model assign high probability to "cat"? If not, backpropagation adjusts both weight matrices.
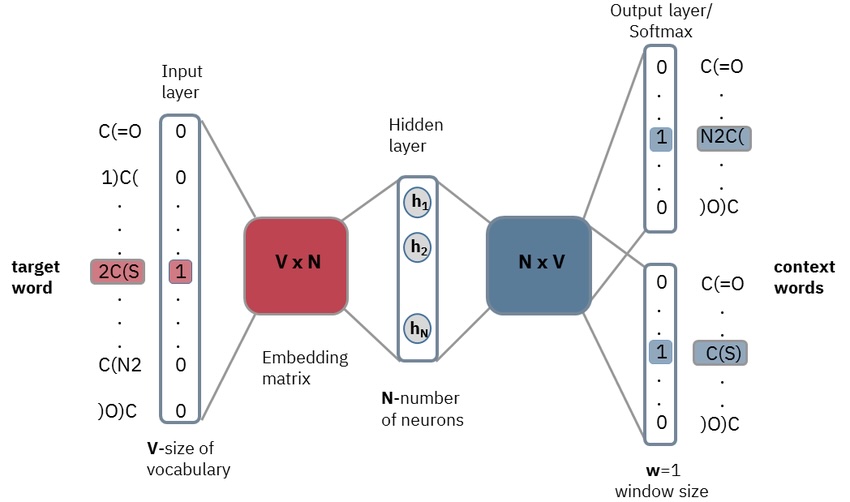
After training, we throw away the decoder (W_context). The encoder weights (W_embed) are the word embeddings. Each row is a word's vector.
From token to embedding
Putting it together - how does raw text become vectors?
"The cat sat" passes through tokenizer to get token IDs [0, 1, 2], then embedding lookup gives us three 300-dim vectors
For "cat" (token ID 1), the lookup selects row 1 from the embedding matrix:
W_embed: dim1 dim2 dim3 ... (300 cols)
ID 0 "the": [ 0.12, -0.34, 0.56, ... ]
ID 1 "cat": [ 0.78, 0.23, -0.11, ... ] ← this row
ID 2 "sat": [ 0.45, 0.67, 0.89, ... ]
... (one row per token in vocabulary)
The tokenizer decides WHAT gets embedded. The embedding matrix learns HOW to represent it.
Thought experiment: Training data matters
Turn to your neighbor: Pick one of these domains. What does "cell" mean there?
- Medical journals: "cell membrane", "cell division", "stem cell"
- Legal documents: "prison cell", "jail cell", "cell block"
- Tech blogs: "cell phone", "cellular network", "spreadsheet cell"
- Biology textbooks: "cell wall", "cell nucleus"
Same word, completely different vectors. The distributional hypothesis means your embeddings are only as good as the text they learned from.
Part 4: Properties of Embeddings
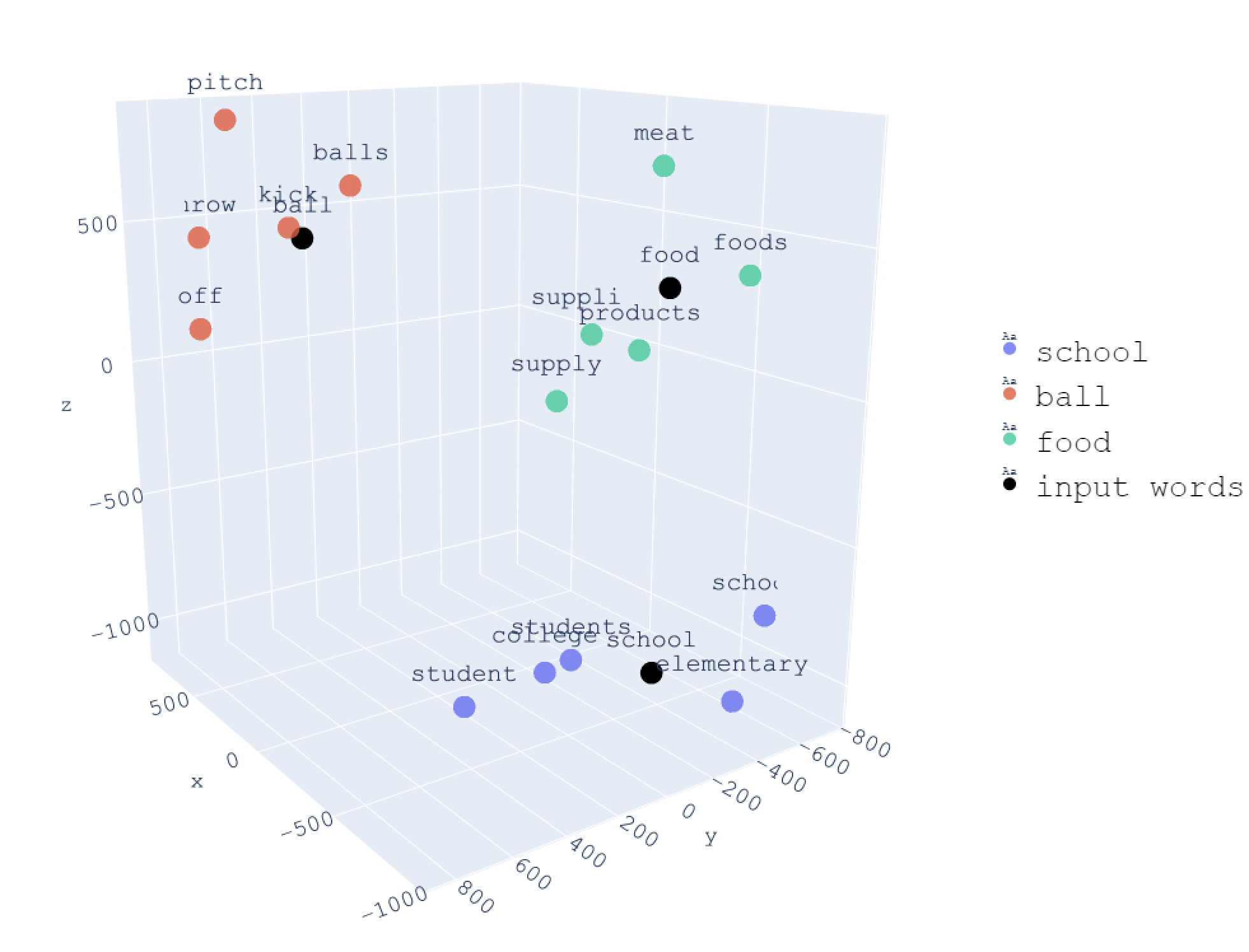
The embedding space
After training, each word is a 300-dimensional vector (typically)
Why 300? More dimensions = more nuance. 50 dimensions might capture "cat is an animal." 300 dimensions can also capture "cat is small, is a pet, is independent, is internet-famous, purrs, has whiskers..."
Example (simplified to 2D for visualization):
"king" -> [0.5, 0.8]
"queen" -> [0.6, 0.7]
"man" -> [0.3, 0.9]
"woman" -> [0.4, 0.8]
"banana" -> [0.9, 0.1]
Similar words are close together in this space
Vector arithmetic: The famous example
king - man + woman ≈ queen
Paris - France + Italy ≈ Rome
better - good + bad ≈ worse
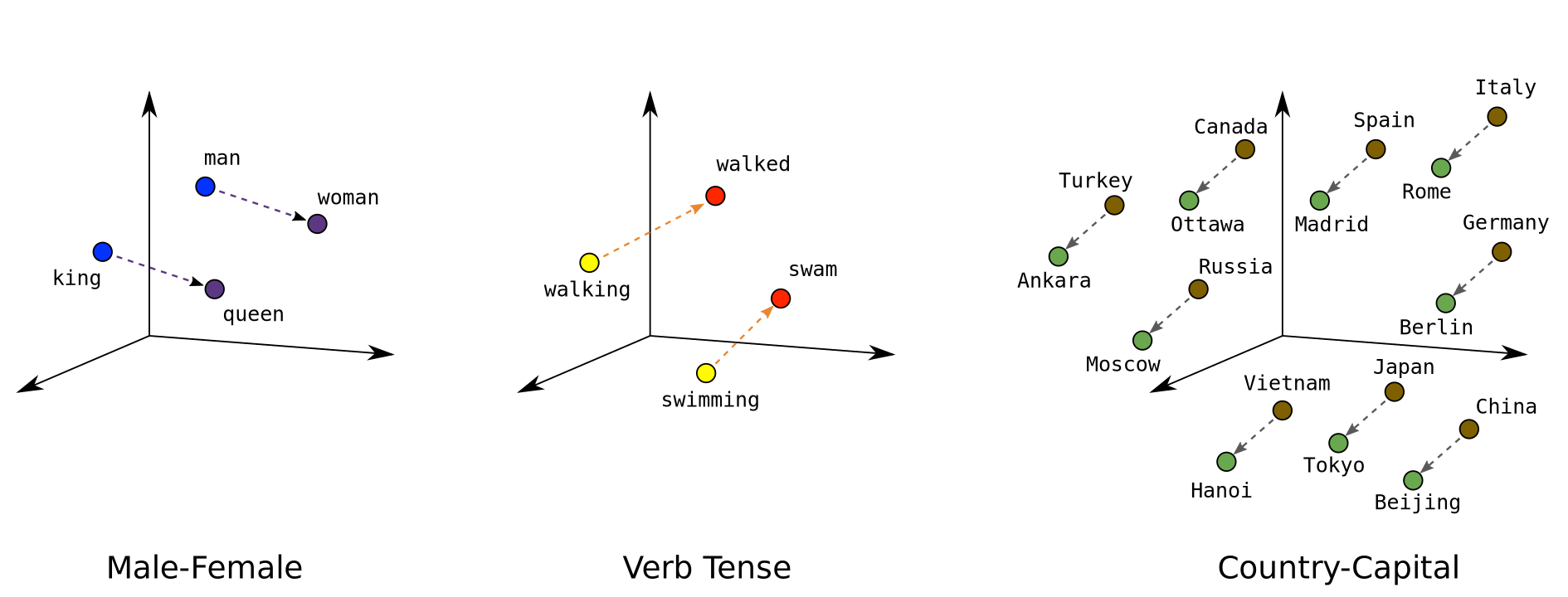
The embeddings capture relationships, not just similarity!
The limitation: One vector per word
Think about this sentence:
"I deposited money at the bank before walking along the river bank."
Word2Vec gives "bank" ONE vector. Same representation for both meanings.
Question: How would you want a smarter system to handle this?
FYI - there are other word embeddings
GloVe (2014) and FastText (2016) used the same distributional hypothesis but with different technical tricks.
FastText is notable for handling out-of-vocabulary words by using character n-grams.
Word2Vec is the most conceptually clear, which is why we focused on it.
Loading word embeddings in python
Let's actually work with pre-trained word vectors!
# Using gensim library
from gensim.models import KeyedVectors
# Load pre-trained vectors
model = KeyedVectors.load_word2vec_format('GoogleNews-vectors.bin', binary=True)
# Find similar words
model.most_similar("king")
# Output: [('queen', 0.65), ('monarch', 0.58), ('prince', 0.55), ...]
# Compute similarity
model.similarity("cat", "dog") # High! ~0.76
model.similarity("cat", "car") # Low ~0.31
# Analogies
model.most_similar(positive=["woman", "king"], negative=["man"])
# Output: [('queen', 0.71), ...]
Challenge: Best and worst analogies
Each pair has a mission:
- Find the most surprising analogy that works
- Find one you expected to work but doesn't
Format: [word1] - [word2] + [word3] ≈ ?
Starting ideas:
- swimming - swim + run ≈ ?
- France - Paris + London ≈ ?
- good - bad + ugly ≈ ?
Also try: projector.tensorflow.org
We'll vote on the best find!
Do modern LLMs use Word2Vec?
No, but they use the same concept.
- GPT, Claude, LLaMA all have an embedding layer as their first layer
- Each token in the vocabulary gets a learned vector (typically 4096+ dimensions now)
- These embeddings are learned during training, not separately
How big is this? GPT-2's embedding table alone:
- 50,257 tokens
- 768 dimensions
- 38.6 million parameters and that's just the first layer of a "small" model
The key difference:
- Word2Vec embeddings are static: "bank" has one vector whether it's a river bank or a money bank
- Modern LLMs start with the same kind of static lookup table, but then transformer layers use attention to build context-dependent representations on top
- By layer 40, "bank" looks completely different depending on whether "river" or "money" is nearby
Where are embeddings used today? (skim)
"If LLMs learn their own embeddings, is Word2Vec obsolete?"
Not quite! Embeddings are still everywhere:
| Application | How embeddings help |
|---|---|
| Search / Retrieval | Find documents similar to a query (semantic search) |
| Recommendations | "Users who liked X also liked Y" |
| RAG systems | Find relevant chunks to feed to an LLM |
| Clustering | Group similar documents automatically |
| Anomaly detection | Find outliers in text data |
E.g. Spotify: Your listening history becomes a point in "music space," and recommendations are nearby points.
When to use pre-trained embeddings vs. LLMs:
- Embeddings: Fast, cheap, good for similarity/search
- LLMs: Slower, expensive, good for generation/reasoning
Part 5: Ethics and Bias in Embeddings
The problem: Embeddings learn human biases
Remember: Embeddings learn from text data
That text reflects human biases
So embeddings encode those biases into the vectors**
We just learned vector arithmetic. Let's try one more:
man - woman + doctor ≈ ???
man - woman + doctor ≈ ?
Result: "nurse"
man - woman + programmer ≈ ?
Result: "homemaker"
These reflect gender stereotypes in the training data
If you're interested, check out the famous paper "Man is to Computer Programmer as Woman is to Homemaker? Debiasing Word Embeddings"
Let's try a few! (And test your embeddings from earlier)
jupyter notebook scripts/embedding_demo.ipynb
Real-world impact: Amazon's recruiting tool
2014-2017: Amazon built AI to screen resumes
Trained on: Historical resumes (mostly from men, especially in tech roles)
Result: The model learned to penalize:
- The word "women's" so "women's chess club captain" was a red flag
- Graduates of all-women's colleges
- Any signal correlated with being female
Outcome: Amazon scrapped the tool in 2017
This isn't a "bug in the algorithm" it's the algorithm doing exactly what we taught it. The bias is in the data.
Discussion: Where do these biases come from?
Turn to your neighbor:
- Why do word embeddings encode bias?
- Where in the pipeline does bias enter?
- What can we do about it?
The bias pipeline
1. Training data reflects historical bias
2. Algorithm accurately learns patterns (including biased ones)
3. Embeddings encode those biases as geometric relationships
4. Downstream applications (hiring, lending, recommendations) amplify bias
The algorithm is doing its job - that's the problem!
Can we "debias" embeddings?
Bolukbasi et al.'s approach:
- Identify a "gender direction" in embedding space
- For neutral words (like professions), remove the gender component
- Preserve gender for definitional words (king/queen, father/mother)
Does this work?
Partially - reduces some measurable biases
But doesn't eliminate them, and may introduce new problems
Hard to define "fair" - what should the "right" associations be?
Have you seen this? Have there been times ChatGPT/Claude/etc. gave you a response that felt stereotypical or made assumptions?
The deeper questions
Open discussion:
Should we try to debias embeddings? Why or why not?
If embeddings accurately reflect reality, is that itself a problem?
Who gets to decide what's "biased" vs "accurate"?
Whose responsibility is this: researchers? companies? users?
There are no easy answers - that's what makes this important
What companies do now
2016 framing: "Debias word embeddings"
2026 framing: "Align LLMs with human values"
| Approach | How it works |
|---|---|
| Data curation | Filter training data for quality and balance |
| RLHF | Train model to prefer "good" outputs (Week 7) |
| Content filters | Block harmful outputs at inference time |
| Red-teaming | Hire people to find problems before users do |
None of these fully solve the problem. Active research area.
Part 6: RNNs - Context You Should Know
The implementation question
We've seen the encoder-decoder framework. We've seen how to learn word vectors.
But here's the problem: neural networks expect fixed-size inputs. Sentences have variable length.
How would YOU feed a sentence into a neural network?
Take 15 seconds to think about it.
How to build the encoder and decoder?
Option 1: Just use feed-forward networks
- Problem: Can't handle variable length sequences!
Option 2: Recurrent Neural Networks (RNNs)
- Process sequences one step at a time
- Maintain "hidden state" that carries information
- This was the dominant approach 2014-2017
Option 3: Transformers with attention
- This is what won (2017+)
- We'll finally dig into this starting Wednesday
RNNs in 60 seconds
Before transformers (2014-2017), RNNs were how we processed sequences.
The idea: Process tokens one at a time, maintaining a "hidden state" that carries information forward.
"I" -> h1
"love" & h1 -> h2
"NLP" & h2 -> h3
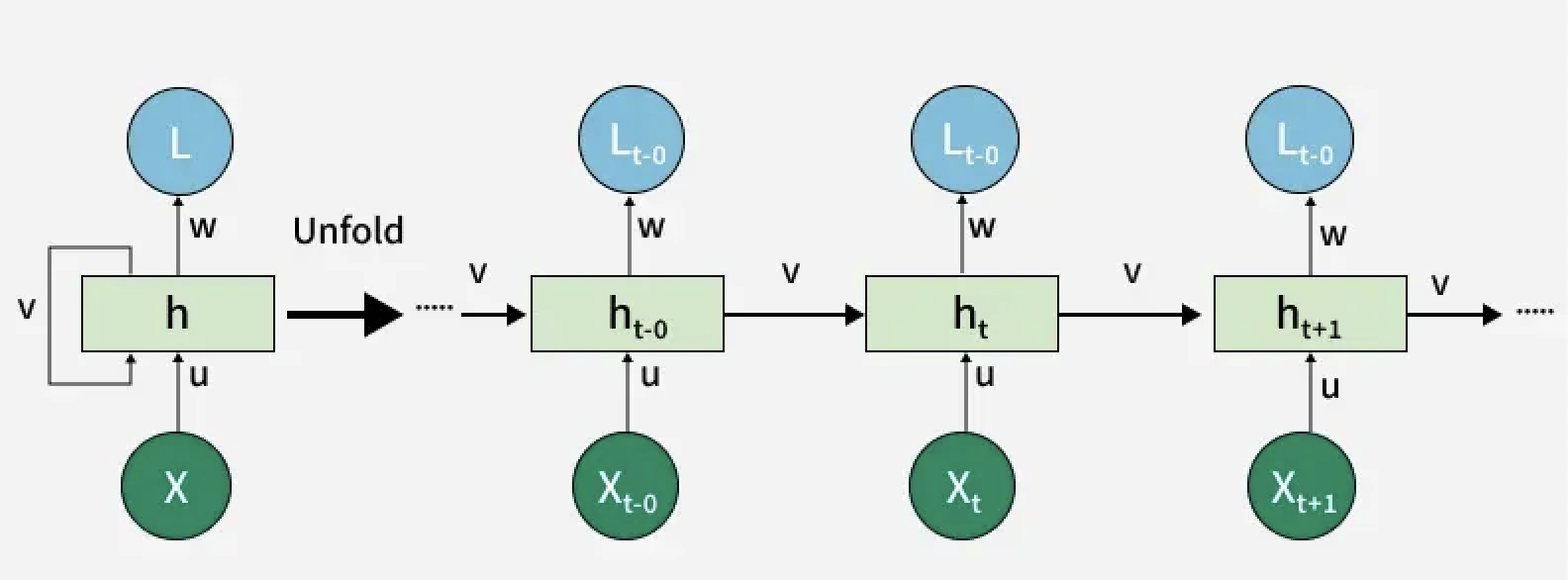
You don't need to know the math. Just know they existed and why they lost.
If you're curious - check out Andrej Karpathy's excellent (viral) blog post "The Unreasonable Effectiveness of RNNs"
Why transformers replaced RNNs
Can't parallelize
- Each token waits for the previous. Can't parallelize across a sentence.
- A 10T parameter model like GPT-5 would take hundreds of years to train.
Vanishing gradients
- Information from early tokens fades.
- Hard to connect "The cat that..." to "...was hungry" 50 words later.
Context bottleneck
- Entire input compressed to one context vector
- Same problem we discussed - can't fit a novel into 512 numbers
LSTMs/GRUs helped with gradients but didn't fix parallelization or bottleneck.
The solution: Attention (Wednesday!)
Attention lets the model:
- Process all tokens in parallel (fast!)
- Look directly at any input token when generating output (no bottleneck!)
- Learn which tokens are relevant to which (better long-range connections!)
This is why we have modern LLMs. Without attention, GPT-5 couldn't exist.
What we've learned today
Distributional hypothesis: words in similar contexts have similar meanings
Encoder-decoder framework for sequence-to-sequence tasks
Word2Vec: train neural networks to predict context, learn embeddings
Embeddings encode societal biases from training data
RNNs briefly (transformers replaced them!)
Connecting the dots
Lecture 2: Classical NLP (counting, BoW, n-grams)
Lecture 3: Neural networks (the learning machinery)
Lecture 4: Tokenization (how we break text into pieces)
Lecture 5 (today): Embeddings + encoder-decoder (putting it together for sequences)
Wednesday: Attention, the key ingredient in transformers
Lab/reflection for week 4 due Friday
- Explore sequence-to-sequence concepts and word embeddings
- Use pre-trained embeddings (gensim) for exploration
- Experiment with encoder-decoder concepts
- Try to build a network with an attention mechanism by hand (play around!)