Lecture 7 - Transformer Architecture
Welcome back!
Last time: Attention, self-attention, multi-head attention
Today: Full transformer architecture
Why this matters: Every major LLM uses transformers (GPT, BERT, Claude, Gemini)
Logistics
- Portfolio piece due Friday (slash Sunday)
- Scope ~ blog post
- Decoding and midterm review tomorrow
- Exam Monday
| Section | Topic | Points |
|---|---|---|
| 1 | Text Representation | 20 |
| 2 | Attention Mechanisms | 20 |
| 3 | Transformer Components | 20 |
| 4 | Decoder & Generation | 20 |
| 5 | Responsible AI | 20 |
Ice breaker (think/pair/share)
What differences have you noticed across LLM models - from GPT-2/3 to today's models?
Agenda for today
- Recap + Data flow: From text to Q/K/V
- Building blocks: Positional encoding, residual connections, layer norm, FFN
- Full architecture: Encoder and decoder deep dive
- Hands-on: Drawing the transformer together
Part 1: Recap and Data Flow
Monday's key ideas
Cross-attention: Decoder attends to encoder
- "What input is relevant to what I'm generating?"
Self-attention: Sequence attends to itself
- "How do words relate to each other?"
Multi-head attention: Multiple attention heads in parallel
- Different heads capture syntax, semantics, position
The formula:
Today: How these pieces snap together
But first: where do Q, K, V come from?
I was clear about: Attention formula, combining Q, K, V
I was not clear about: Where do we GET Q, K, V?
So let's track the complete flow
From raw input to embeddings
Starting point: "snow melts"
Let's assume the size of our embeddings is
Step 1: Tokenization
- ["snow", "melts"], one-hot encoded gives us a $2 \times 50,000(50,000 \times 512) \to 2 \times 512(2 \times 512)$
From embeddings to Q, K, V
(Assuming self-attention)
Three learned projection matrices: $W_QW_KW_V)
- Project embedding into query space
- Project embedding into key space (for matching)
- Project embedding into value space (for content)
Projection matrices are learned during training
Now we can use the attention formula
Once we have Q, K, V:
Let's draw it out
You try first:
Sketch the flow for your own 2-word sentence:
- Start with text
- Tokenization
- Embedding matrices and embeddings
- and
- Attention formula and final output
What are the matrix dimensions at each step?
Then we'll draw on the board together
Quick reminder: Multi-head attention mechanics
Inside "Multi-Head Attention":
- Split into h heads (typically 8)
- Each head runs attention independently with own projection matrices
- Concatenate all head outputs
- Project with output projection matrix
Result: Each head focuses on different aspects (syntax, semantics, position)
Output dimension: Still (512), same as input
Dimension notation: vs
Important terminology clarification:
= full model dimension (typically 512)
- Size of token embeddings
- Input/output size of each transformer layer
- Also called or embedding dimension
= dimension per attention head (typically 64)
- With 8 heads and : each head gets
- Appears in the scaling factor: in the attention formula
Relationship: where = number of heads
The building blocks for a complete transformer
- Self-attention: Each position attends to all positions
- Multi-head attention: Multiple attention mechanisms in parallel
New today:
- Positional encoding: Add position information
- Feed-forward networks: Process each position independently
- Layer normalization + residual connections: Stabilize training
Next: Understand the new pieces, then assemble
Part 2: Building Blocks
Positional Encoding: The order problem
Problem: Attention doesn't perceive sequence order
"The cat sat on the mat" and "mat the on sat cat The" have equivalent representations
Why? Attention just looks at relationships, not order
Solution: Positional encoding
Idea: Add positional information to embeddings
Before: X = [embedding for "cat", embedding for "sat", ...]
After: X = [embedding + position 0, embedding + position 1, ...]
Result: Model knows "cat" at position 0, "sat" at position 1
How to encode position?
Option 1: Learned embeddings (modern models)
Option 2: Fixed sinusoidal functions (original paper)
Sinusoidal positional encodings
FYI / you're not responsible for these formulas:
Intuition: Different frequencies create unique "fingerprints" for each position
Why this works: Model can learn absolute and relative positions
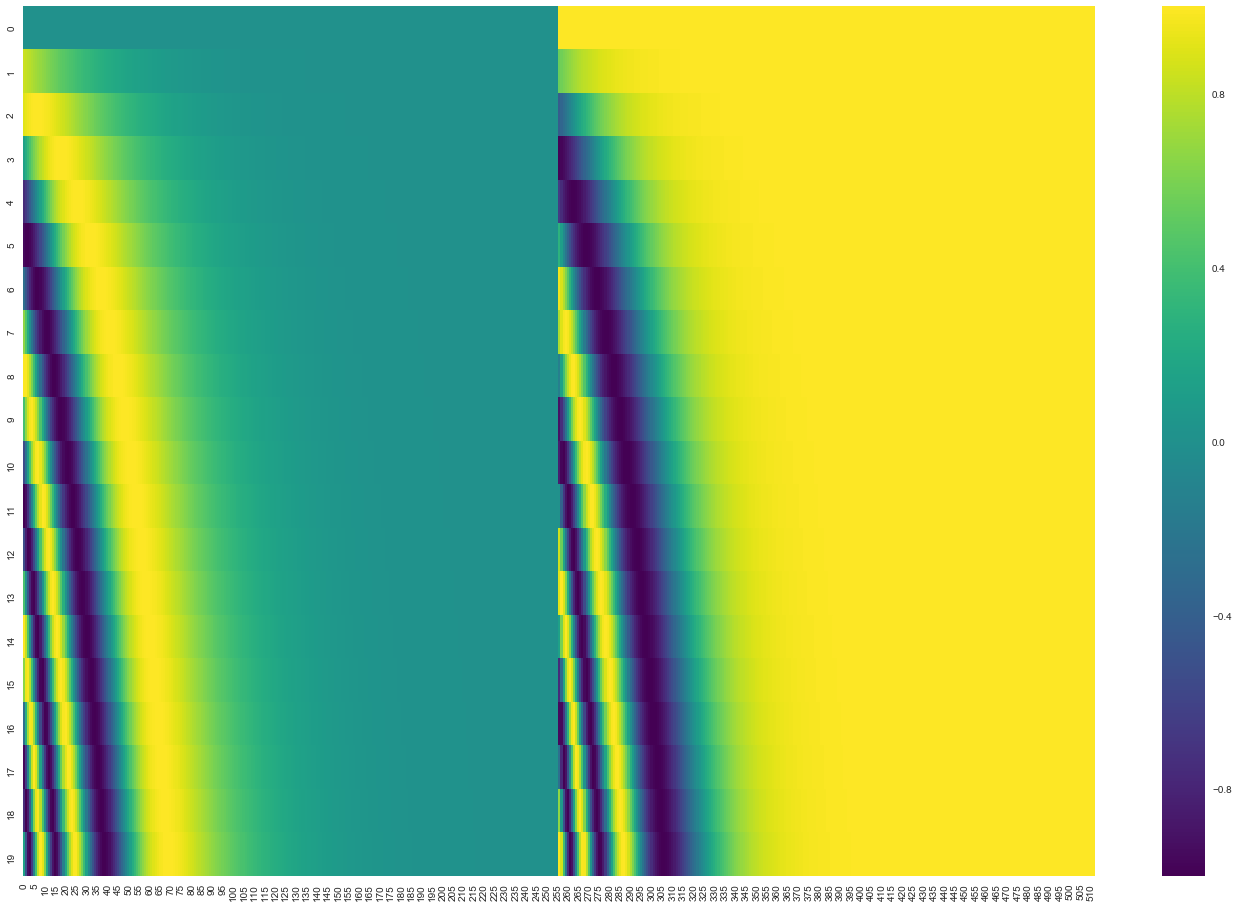
Embeddings + positional encoding
-
Token embeddings:
-
Positional encodings:
-
Add them: input = embeddings + positional encodings
-
Pass to rest of model
Result: Each token embedding has WHAT it is (word) and WHERE it is (position)
Positional encoding added at input to BOTH encoder and decoder
Residual connections
Problem: Deep networks hard to train (vanishing gradients)
Solution: Add input back to output
Instead of: output = Layer(input)
We do: output = input + Layer(input)
input ───┬───> [Layer] ───> (+) ───> output
│ ↑
└───────────────────┘
(residual / skip connection)
Why this helps: Model can ignore unhelpful layers (set contribution ≈ 0)
Also helps gradients flow backward during training
In transformers: EVERY sublayer (attention, FFN) has residual connection
Layer normalization
After each sublayer:
- Rescale to mean = 0, variance = 1
- Stabilizes training (prevents values getting too large/small)
In transformers: Layer norm happens AFTER residual connection
Full pattern: output = LayerNorm(input + Sublayer(input))
Feed-forward network (FFN)
After attention, EACH POSITION goes through small neural network:
Structure:
- Input: (e.g., 512)
- Hidden layer: (e.g., 2048) - much wider!
- Output: (e.g., 512)
- Activation: ReLU (the max(0, ...))
Key: Applied to each position INDEPENDENTLY. Same FFN weights shared across all positions, different inputs per position
The FFN is just a 2-layer neural network (also called a multi-layer perceptron or MLP)
Pattern: Attention mixes info ACROSS positions, FFN processes each position individually (adds capacity and non-linearity)
FFN much wider than model dimension (This is where many parameters live)
Quick break: What surprises you?
Turn to your neighbor (2 min):
You've now seen all the building blocks: attention, positional encoding, residual connections, layer norm, FFN.
- What surprised you?
- What seems clever?
- What seems redundant or over-engineered?
Share with class: Any "aha" moments or lingering confusion?
Part 3: Full Transformer Architecture
The complete picture
Original transformer: Encoder-Decoder architecture for translation
Full diagram first, then build up piece by piece:
From "Attention is All You Need":
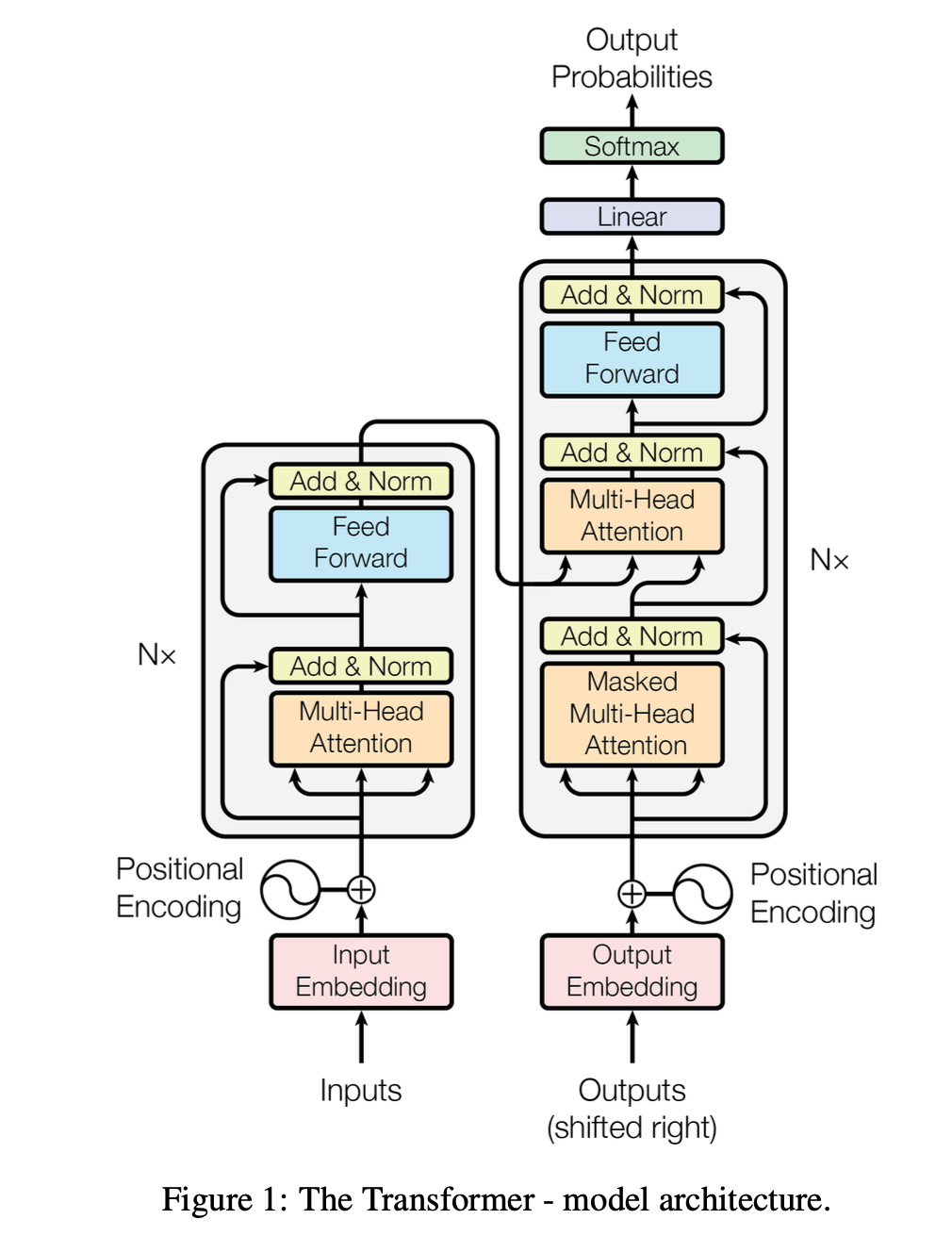
Encoder block components
Each encoder block has TWO sublayers:
-
Multi-head self-attention
- Input sequence attends to itself
- Each position can see all positions
-
Feed-forward network (FFN)
- FFN per position independently
- Typically: 512 to 2048 to 512
Both sublayers have:
- Residual connection (add input to output)
- Layer normalization
What is "encoder output"?
- After 6 stacked blocks: matrix
- Each row = processed embedding of one input token
- Entire matrix feeds into decoder's cross-attention (used as K and V)
- Encoder runs ONCE, output reused at every decoder step
Decoder block components
Each decoder block has THREE sublayers:
-
Masked multi-head self-attention
- Output tokens attend to previous tokens only
- Can't see future (prevents cheating!)
-
Multi-head cross-attention - Connection to encoder!
- Decoder attends to encoder output
- Q from previous layer (masked self-attention output)
- K and V from encoder output (processed input)
-
Feed-forward network (FFN)
- Same as encoder
All three sublayers: Residual connections + layer norm
Why masked? During generation we don't know future tokens yet!
Encoder vs Decoder: Key differences
Similar building blocks, important differences:
| Component | Encoder | Decoder |
|---|---|---|
| Input | Entire source sequence | Output tokens generated so far |
| Self-attention | Can see all positions | Masked (can't see future) |
| Cross-attention | None | Attends to encoder output |
| Sublayers per block | 2 (self-attn + FFN) | 3 (masked self-attn + cross-attn + FFN) |
| Purpose | Build rich representation | Generate output one token at a time |
Both: 6 stacked blocks, residual connections, layer norm
Learned vs computed parameters
Important distinction:
Learned during training (model parameters):
- projection matrices (in each attention layer)
- output projection matrix (in multi-head attention)
- FFN weights ()
- Layer norm parameters (scale and shift)
- Embedding matrices
Computed during forward pass:
- Q, K, V matrices (from , , )
- Attention weights (softmax of )
- Attention output (weighted sum of V)
From decoder to predictions
After 6 decoder blocks, how do we get next token?
Step 1: Decoder output
- After all 6 blocks: matrix
- Still in embedding space (512 dimensions)
Step 2: Linear projection
- Learned weight matrix:
- Maps embedding space to vocabulary space
- Output:
Step 3: Softmax
- Creates probability distribution over vocabulary per position
Step 4: Select next token
- Sample or argmax to pick actual token (we'll see more next time)
Autoregressive generation in action
Translating "snow melts" into "la neige fond"
Step 0: Encoder processes "snow melts" ONCE to get encoder output E
Step 1:
- Decoder input: [START]
- Processes: masked self-attn on [START], cross-attn to E, FFN
- Output: "la" (predicted)
Step 2:
- Decoder input: [START, "la"]
- Processes: masked self-attn on [START, "la"], cross-attn to E, FFN
- Output: "neige" (predicted)
Step 3:
- Decoder input: [START, "la", "neige"]
- Processes: masked self-attn on [START, "la", "neige"], cross-attn to E, FFN
- Output: "fond" (predicted)
Encoder output E constant. Only decoder input grows
Let's think about - what are the decoder's INPUTS?
Decoder has TWO separate input sources:
Input 1: From encoder (via cross-attention)
- Encoder processes "snow melts" ONCE to get encoder output
- This output REUSED at every decoder step
- Used in cross-attention layer (K and V)
Input 2: Decoder's own previous outputs (via masked self-attention)
- Starts with [START] token
- Grows: [START], then [START, "neige"], then [START, "neige", "fond"]
- Each token attends to all previous in THIS sequence
- Used in masked self-attention layer
Encoder runs ONCE. Decoder runs MULTIPLE times (once per output token)
What exactly feeds back?
What gets added to decoder input at each step?
The predicted TOKEN (after sampling/argmax from probability distribution)
Complete loop:
- Decoder outputs hidden states
- Linear projects to vocabulary
- Softmax gives us probabilities over vocabulary
- Sample or argmax to get predicted token (e.g., "la")
- Convert token to embedding (via embedding matrix)
- This embedding added to decoder input for next step
Not probabilities or raw hidden states, but embedded token
Training vs Inference
What you just saw: INFERENCE (generating one token at a time)
During TRAINING, it's different:
Training:
- Have full target: [START, "la", "neige", "fond"]
- Decoder processes ENTIRE sequence at once (with masking)
- Each position predicts next token in parallel
- Fast and efficient!
Inference (generation):
- Generate one token at a time
- Decoder runs sequentially (once per output token)
- Slower but necessary (don't know answer yet!)
Why training fast (parallel) but generation slow (sequential)!
Quick check: Trace the flow (pairs, 5 min)
Turn to your neighbor, trace through:
Input: "snow melts" (English), Output: "neige fond" (French)
Answer together:
-
"snow" through encoder block - what TWO sublayers?
-
Decoder generates "fond" - which THREE attention mechanisms?
-
Where does positional encoding get added?
-
What's the purpose of cross-attention?
-
How many times encoder run? Decoder run?
Drawing Practice
Now YOU draw the architecture!
Work in pairs. Follow step-by-step instructions on handout
Take your time. Best way to absorb this and practice for midterm
Drawing Activity: Your Checklist
Work in pairs. Try to draw from what you remember!
- Input path - how do tokens enter the model?
- One encoder block - what are the two sublayers? What connects them?
- Encoder stacking - how many blocks? What comes out?
- One decoder block - this one has THREE sublayers. What are they? Where does the encoder connect?
- Decoder output path - how do we get from decoder output to a word prediction?
- Label the three types of attention in your diagram
Compare with your partner. Raise hand if questions!
Now let's build it together on the board!
Your turn to teach ME:
I'll draw based on YOUR instructions:
- Where do I start?
- What comes next?
- Did I get this right?
Call out if you see a mistake
What we learned today
Complete data flow: Text → tokens → embeddings → multiply by , , → Q/K/V vectors → attention output
Building blocks: Positional encoding (inject order), residual connections (help training), layer norm (stabilize), FFN (add capacity)
Encoder blocks (2 sublayers): Self-attention + FFN. Runs ONCE, produces rich representation
Decoder blocks (3 sublayers): Masked self-attention + cross-attention + FFN. Runs MULTIPLE times, generates one token at a time
Training vs inference: Training uses "teacher forcing" (parallel), inference is autoregressive (sequential)
Logistical notes
Recommended:
- Review Jay Alammar's "Illustrated Transformer" post
- Try sketching transformer architecture from memory
Portfolio Piece 1 Due Friday/Sunday
Quick reflection due too! Friday/Sunday
Exam 1: Monday, Feb 23 (everything through transformers & decoding)
Appendix: Full Step-by-Step Drawing Instructions
Use this to check your work or practice at home.
Step 1: Input path (both encoder and decoder)
- Box: "Input tokens" (e.g., "snow melts")
- Arrows point to "Embedding + Positional Encoding"
- Note dimensions: , typically = 512
Step 2: Draw ONE encoder block (vertically)
- Box: "Multi-Head Self-Attention"
- Show residual connection: arrow AROUND it
- Box: "Add & Norm"
- Box: "Feed-Forward Network (FFN)"
- Show residual connection: arrow around FFN
- Box: "Add & Norm"
Step 3: Show encoder stacking
- Write "×6" next to encoder block (or draw 2-3 stacked)
- Label output: "Encoder Output" (feeds into decoder)
Step 4: Draw ONE decoder block
- Box: "Masked Multi-Head Self-Attention" (can't see future)
- Residual connection + "Add & Norm"
- Box: "Multi-Head Cross-Attention"
- IMPORTANT: Arrow FROM encoder output TO this layer
- Residual connection + "Add & Norm"
- Box: "Feed-Forward Network (FFN)"
- Residual connection + "Add & Norm"
Step 5: Complete decoder output path
- Write "×6" for decoder stacking
- Arrow to "Linear" (projects to vocab size)
- Arrow to "Softmax"
- Output: "Probability distribution over vocabulary"