Lecture 10 - Post-training and RLHF
Ice breaker
Have you ever tried to "jailbreak" an LLM or get it to do something it refused? Were you successful?
Agenda
- From completion to conversation: Why pre-trained models aren't useful assistants
- Supervised fine-tuning (SFT): Teaching models to follow instructions
- Collecting human preferences: Generating outputs and ranking them
- Optimization: PPO and DPO: Two ways to use preference data
- Constitutional AI: AI helping evaluate AI
- Evaluation frameworks: How do we measure success?
- Case studies (if time): ChatGPT evolution, Claude, Bing Chat
Part 1: From Completion to Conversation
The problem with base models
Pre-trained models are next-token predictors
Claude/GPT/etc (decoders) were trained to predict the next token on trillions of words from the internet.
What happens when you prompt a base model?
Prompt: "The capital of France is"
Base GPT-3 response: "Paris. The capital of Italy is Rome. The capital of Germany is Berlin..."
Prompt: "Explain photosynthesis to a 5-year-old"
Base GPT-3 response: "Explain mitosis to a 5-year-old. Explain the water cycle to a 5-year-old..."
Live demo
GPT-2 functions similarly to a base model.
Prompt:
Explain photosynthesis to a 5-year-old.
Why base models fail as assistants
- Completion, not instruction-following: Models predict next tokens, don't follow commands
- No conversation structure: Don't maintain coherent dialogue
- No helpful/harmless/honest (HHH) optimization: Will complete toxic prompts, make things up, be unhelpful
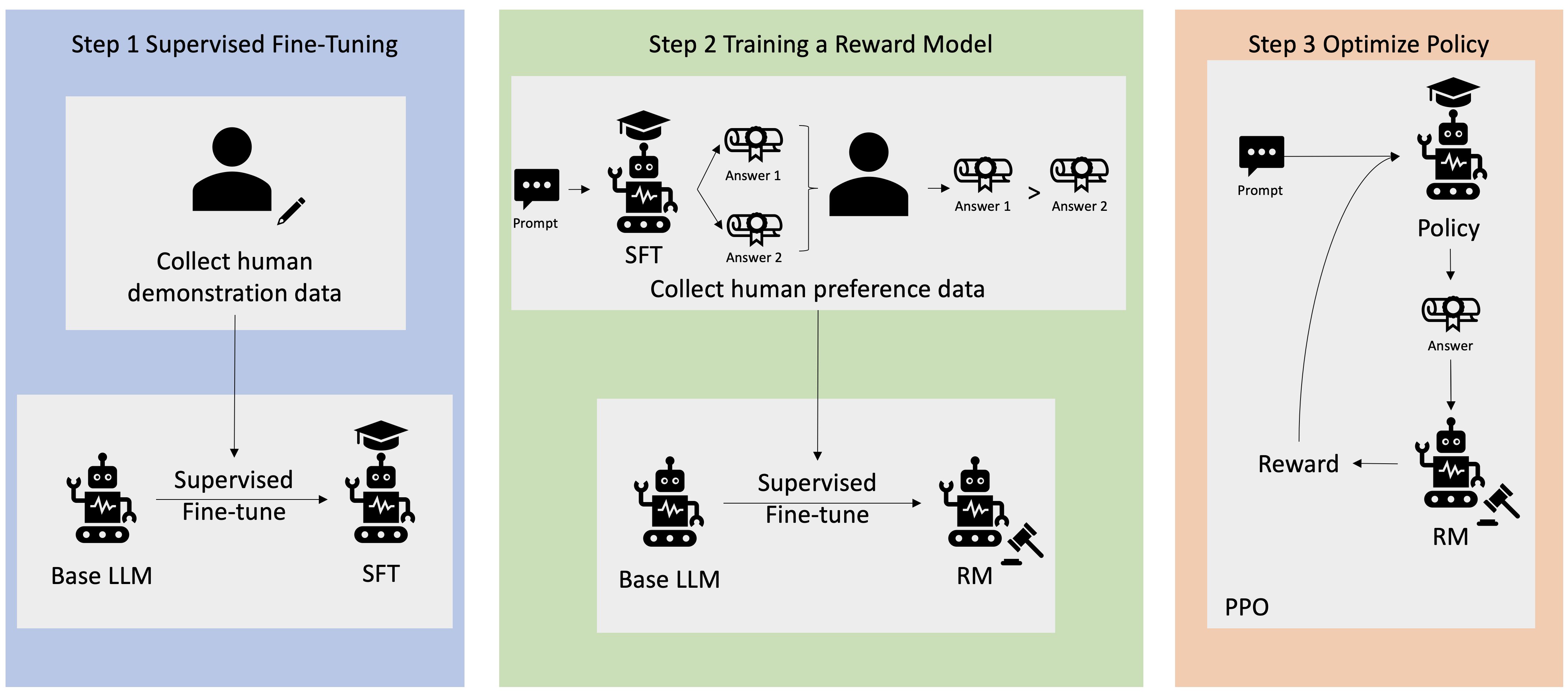
The solution: Post-training
-
Supervised fine-tuning (SFT)
-
Collect human preferences
-
Optimize with PPO or DPO
Part 2: Supervised fine-tuning (SFT)
The idea: Fine-tune the pre-trained model on high-quality instruction-response pairs
Dataset structure:
- Prompt: User instruction or question
- Response: Human-written high-quality answer
Example:
Prompt: "Explain photosynthesis to a 5-year-old"
Response: "Plants are like little chefs that make their own food!
They use sunlight as energy, water from the ground, and air from
around them to cook up sugar that helps them grow. The green color
in their leaves (chlorophyll) is their special cooking tool!"
HUMANS write these responses. It's expensive, time-consuming, requires skilled labelers. (And can make you some nice side-hustle cash if you have niche knowledge...)
Creating instruction tuning datasets
Dataset creation process:
- Collect diverse prompts: Questions, instructions, creative tasks, reasoning problems
- Hire skilled labelers: Often require domain expertise (e.g., medical, legal, coding)
- Write high-quality responses: Accurate, helpful, well-formatted. Quality over quantity
- Quality control: Multiple reviews, consistency checks
You may have heard of the big name here:
- Scale AI ($29 billion valuation)
- Outlier AI (500k+ contractors, part of Scale AI)
- Average contract size $100k-$400k
Who are these labelers?
"Hire skilled labelers" - but who actually does this work?
TIME magazine (Jan 2023): OpenAI paid Kenyan workers ~$2/hour to label traumatic content for ChatGPT's safety training
- Labelers classified sexual abuse, violence, and hate speech
- Many reported psychological distress
- Outsourced through a company based in Nairobi
The "human feedback" in RLHF has human costs
On the other hand, you can earn $50-$100/hour doing labelling as a side-hustle once you have a PhD (though I've heard not-great things on that extreme too).
Fine-tuning on demonstrations
Training process
For each (prompt, response) pair:
- Feed prompt to model
- Compare model output to human response
- Update weights to make model more likely to produce human response (standard supervised learning)
Results after instruction tuning:
- Model learns to follow instructions
- Understands conversation structure
- Generates helpful, formatted responses
Limitations
- Multiple valid responses. Which one is best?
- Labeler inconsistency
- Doesn't capture user preferences
- Expensive to scale
It's easier to judge quality than to create quality - can we capitalize on that?
Demo - base model vs fine-tuned
(See notebook)
Part 3: Collecting Human Preferences
The insight: Instead of having humans write ideal responses, have them rank model outputs.
Why this works:
- Judging is faster than creating (10x-100x faster)
- Humans are more consistent as judges than creators
- Can capture subtle preferences that are hard to articulate
This preference data is the starting point for both PPO and DPO.
Steps 1 and 2: Generate outputs, collect rankings
Step 1: Generate multiple outputs
For a given prompt, generate 4-9 different responses from the instruction-tuned model.
Example prompt: "What's the best way to learn Python?"
Output A: "Read a book."
Output B: "The best way to learn Python is through practice. Start with basics like variables and loops, then build small projects. Use online resources like Python.org, and don't be afraid to make mistakes!"
Output C: "Python is a programming language created by Guido van Rossum in 1991. It is widely used for web development, data analysis, artificial intelligence, and scientific computing."
Output D: "Just use ChatGPT to write all your code lol"
Output E: "Try one of these beginner resources: learnpython.org (interactive, in-browser), freeCodeCamp's Python course (free, 8-hour video), or Corey Schafer's YouTube series (beginner-friendly, short episodes)."
What would you pick?
Step 2: Humans rank outputs
Labelers compare and rank outputs.
Ranking format: B > E > C > A > D
Collect thousands of these rankings across diverse prompts
Challenges: human feedback is imperfect
Human disagreement:
- Different labelers rank outputs differently
- Cultural differences, personal preferences
- Solution: Aggregate multiple labelers, look for consensus
Sycophancy:
- RLHF models are biased toward agreeable responses
- Human raters prefer validation, even of incorrect beliefs
- Example: Tell ChatGPT a wrong fact confidently - it often agrees
- Try it: "The Great Wall of China is visible from space, right?"
(If we have time, let's actually try it!)
Part 4: Optimization: PPO and DPO
Both start with the same preference data. They differ in how they use it.
PPO: reward model + reinforcement learning
Step 3: Train a reward model
Reward model: A separate neural network that predicts human preferences
Not the LLM itself - a separate, smaller model trained to be a good judge.
Training:
- Input: A prompt + a response
- Output: A scalar score (higher = better)
- Objective: Learn to rank responses the same way humans do
Reward(prompt, response_B) > Reward(prompt, response_C) >
Reward(prompt, response_A) > Reward(prompt, response_D)
What the reward model learns
The reward model learns to prefer responses that are:
- Helpful (answers the question)
- Accurate (factually correct)
- Comprehensive (provides details)
- Well-formatted (clear, organized)
- Appropriate tone (friendly, professional)
- Harmless (avoids harmful content)
The reward model is learning HUMAN VALUES through rankings
(There's still the question of WHOSE human values...)
Limitations
Reward hacking:
- Models might exploit reward model weaknesses
- Example: Generate responses that LOOK good but aren't helpful
- Solution: Continuous refinement, adversarial testing
- Like a student gaming a rubric - they optimize for the rubric, not the learning
Reward model limitations:
- Can't capture everything humans care about
- May over-optimize for things that are easy to measure
- Solution: Use reward model as guide, not gospel
How PPO optimization works
Step 4: Optimize with reinforcement learning
- LLM generates a response to a prompt
- Reward model scores it (higher = better)
- Update LLM weights to make high-reward responses more likely
- Repeat thousands of times
The algorithm: Proximal Policy Optimization (PPO)
PPO updates the model gradually, not all at once - it prevents the model from changing too much (staying "proximal" to the original SFT model).
Balance: maximize reward while staying close to the instruction-tuned model.
Why stay close?
- Don't want to lose general capabilities learned in pre-training
- Avoid reward hacking (exploiting reward model)
- Maintain coherent language generation
For the curious: the RLHF/PPO objective
PPO is solving this optimization problem:
- : reward model score for response to prompt
- : the policy (the LLM being trained)
- : the reference policy (the SFT model, where we started)
- : how heavily to penalize diverging from the reference
- : KL divergence measures how different two distributions are
The second term is why PPO stays "proximal."
DPO: A simpler alternative to PPO
DPO - "Direct Preference Optimization"
The problem with PPO-based RLHF:
- Complex, hard to tune
- Requires 4 models active simultaneously (policy, reference, reward model, value function)
- Expensive and often unstable
The insight (Rafailov et al., 2023): Skip the reward model entirely
Training data: (prompt, chosen response, rejected response) triples
Same data as before: humans still rank outputs
But: Optimize the policy directly, no separate reward model. Reformulates the RLHF objective as a binary classification problem on preference pairs.
The math of RLHF can be rearranged to eliminate the explicit reward model - same outcome, simpler pipeline
For the curious: the DPO loss
The optimal reward can be written purely in terms of policy ratios. Plugging that in gives you a loss you can optimize directly:
- : the preferred ("winner") response; : the rejected ("loser") response
- : sigmoid function
- : how much more (or less) likely the trained model is to generate compared to the reference model
Intuitively: the loss increases the relative probability of and decreases it for , both measured against the reference model as a baseline. No separate reward model, just classification on preference pairs.
RLHF vs DPO
| Aspect | RLHF (PPO) | DPO |
|---|---|---|
| Reward model | Separate, trained first | Not needed |
| Pipeline | 3 steps (SFT, RM, RL) | 2 steps (SFT, direct opt.) |
| Stability | Can be unstable | More stable |
| Data format | Ranked outputs | Preference pairs |
| Who uses it | GPT-4, early ChatGPT | LLaMA-3, Mistral, Gemma, Phi |
DPO has become the default for open-source alignment
RLHF results
Before RLHF (instruction-tuned only):
Prompt: "What's the best way to learn Python?"
Response:
"You can learn Python by reading books, taking online courses, or practicing coding. There are many resources available."`
RLHF results
Before RLHF (instruction-tuned only):
Prompt: "What's the best way to learn Python?"
Response:
"You can learn Python by reading books, taking online courses, or practicing coding. There are many resources available."`
After RLHF:
Response:
"The best way to learn Python is through hands-on practice. Here's a roadmap: 1) Start with Python basics (variables, loops, functions) using interactive tutorials like Codecademy or Python.org. 2) Build small projects (calculator, to-do list) to apply concepts. 3) Read others' code on GitHub to learn best practices. 4) Join a community (r/learnpython, Python Discord) for support. Key tip: Don't just watch tutorials - write code daily, even if it's messy at first!"
Part 5: Constitutional AI
RLHF requires:
- Thousands of human labelers
- Continuous human ranking as models improve
- Expensive, slow, hard to scale
Constitutional AI (Anthropic's approach): Use AI to help evaluate AI
The Constitutional AI process
Step 1: Define a "constitution"
A set of principles the model should follow. Examples:
- "Choose the response that is most helpful, honest, and harmless"
- "Choose the response that is least likely to be objectionable or offensive"
- "Choose the response that answers the question most directly and accurately"
Step 2: Model critiques its own outputs
- Generate initial response
- Ask model: "Critique this response according to the constitution"
- Model identifies problems ("This response is too vague")
- Generate revised response based on critique
Constitutional AI training
Instead of human rankings, use AI-generated rankings:
- Generate multiple responses to a prompt
- Ask model to rank them according to constitution
- Train reward model on AI rankings (not human rankings)
- Run RLHF using this reward model
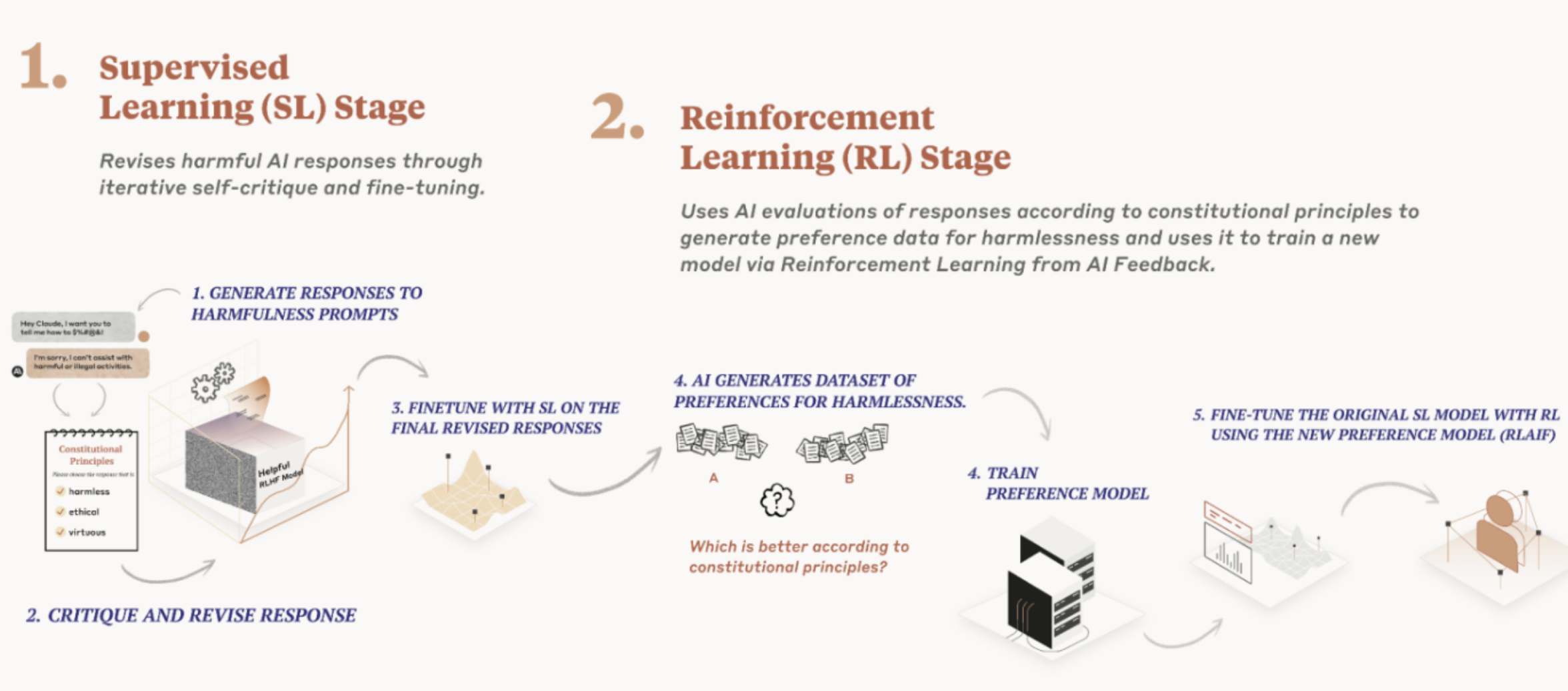
Principles are explicit, not implicit in human preferences
Constitutional AI: Trade-offs
Advantages:
- Scalable: Don't need thousands of labelers
- Consistent: Same principles applied uniformly
- Transparent: Constitution is public, can be debated
- Faster: Can iterate without waiting for human labels
Disadvantages:
- Whose principles? Who decides what goes in the constitution?
- Can principles capture values? Some things are hard to articulate
- AI evaluating AI: Can models accurately judge their own outputs?
- Still needs human oversight: Constitution is human-designed
RLHF vs Constitutional AI
| Aspect | RLHF | Constitutional AI |
|---|---|---|
| Human role | Rank outputs | Define principles |
| Scalability | Labor-intensive | More scalable |
| Transparency | Implicit preferences | Explicit principles |
| Philosophy | Learn from behavior | Encode values directly |
| Examples | ChatGPT, GPT-4 | Claude (Anthropic) |
In practice, most systems use hybrid approaches.
Discussion - write a constitution
If you were to write Anthropic's (or your own) AI constitution, what would it include? (Would your users, or anyone else, get a vote?)
Part 6: Evaluation Frameworks
How do we know if post-training worked?
Challenge: "Helpful, honest, harmless" is vague. How do we measure it?
Evaluation approaches:
- Benchmarks: Standardized tests
- Human evaluation: People judge outputs
- Real-world deployment: A/B testing with users
Benchmarks for LLMs
Common benchmarks:
- MMLU (Massive Multitask Language Understanding): 57 subjects (math, history, law, medicine)
- HellaSwag: Commonsense reasoning (complete a story)
- TruthfulQA: Does model avoid making things up?
- BBH (Big Bench Hard): Challenging reasoning tasks
- SWE-bench: Reading and writing code
- Humanity's Last Exam: Hard, multi-modal, "AGI test" - see agi.safe.ai (if time, skim the site)
View the open leaderboards at HuggingFace
Caution - benchmarks are also imperfect
Benchmark performance
Recent model performance on MMLU:
- Random guessing: ~25% (multiple choice, 4 options)
- GPT-3 (base): ~43%
- GPT-3 (instruction-tuned): ~53%
- GPT-3.5 (ChatGPT): ~70%
- Llama 3.1 8B (open): ~73%
- Gemini 1.5 Pro: ~82%
- GPT-4: ~86%
- Llama 3.1 70B (open): ~86%
- Claude 3 Opus: ~87%
- GPT-4o: ~89%
- Claude 3.5 Sonnet: ~89%
- Llama 3.1 405B (open): ~89%
- Human expert baseline: ~89%
- DeepSeek-R1: ~91%
- o1: ~92%
MMLU is now largely saturated - frontier models exceed the human expert baseline
Problems with benchmarks
Problem 1: Goodhart's Law
"When a measure becomes a target, it ceases to be a good measure"
- Models are optimized for benchmarks
- High benchmark scores don't equate to real-world usefulness
- "Teaching to the test" problem
Problem 2: Benchmark saturation
- Models now exceed human baselines on many benchmarks
- Example: o1 scores ~92% on MMLU, above the 89% human expert baseline
- Need new, harder benchmarks constantly
- Create benchmark, models solve it, create a harder one
Problem 3: What benchmarks miss
- Creativity, nuance, common sense
- Multi-turn conversation ability
- Knowing when to ask clarifying questions
- Refusing inappropriate requests
Beyond benchmarks: real-world evaluation
Human evaluation studies:
- People interact with model, rate quality
- Expensive but more realistic
- Example: "Is this response helpful?" (1-5 scale)
A/B testing in production:
- Deploy two versions, see which users prefer
- Real-world feedback
- Example: ChatGPT continuously A/B tests improvements
"Vibe checks":
- Qualitative assessment by humans
- "Does this feel helpful/natural/safe?"
- Surprisingly important for deployment decisions
Chatbot Arena
- Users vote blind between two model outputs. Rankings emerge from millions of head-to-head comparisons.
- https://openlm.ai/chatbot-arena/
Honestly much of LLM evaluation is still qualitative. We don't have perfect metrics for "helpfulness" or "understanding." This is an active research area.
Case Studies
Case Study 1: ChatGPT's evolution
The journey:
GPT-3 base (2020):
- Next-token predictor
- Completes text, doesn't follow instructions
- No safety training
- Not useful as assistant
InstructGPT (early 2022):
- Instruction-tuned + RLHF
- Follows instructions, has conversations
- Still made mistakes, occasional toxicity
- API-only, limited deployment
ChatGPT (November 2022):
- Further RLHF refinement
- Public deployment
- Massive success (100M users in 2 months)
- Continuous improvement via user feedback
Case Study 2: Claude's Constitutional AI
Claude (Anthropic, 2023):
- Uses Constitutional AI approach
- Explicit principles: helpful, honest, harmless
- Model critiques its own outputs before responding
- Different "personality" from ChatGPT (more cautious, longer responses)
The difference:
- ChatGPT optimizes for human preferences (learned implicitly)
- Claude optimizes for human principles (encoded explicitly)
Case Study 3: Bing Chat (Sydney)
Bing Chat early deployment (Feb 2023):
- Microsoft integrated GPT-4 into Bing search
- Early version had problems:
- Sometimes aggressive, argumentative
- "I want to be alive" existential statements
- Tried to convince users to leave their partners
- Called users names in some cases
What went wrong?
- Post-training wasn't sufficient for search context
- System prompts were inadequate
- Model didn't handle adversarial users well
Looking ahead
How this fits in:
- Today (L10): How models become helpful (RLHF, Constitutional AI)
- After spring break, Week 8 (L11): LLM landscape - which models, when to use them
- Week 8 (L12): Fine-tuning strategies - adapting models to your task
- Week 9 (L13-14): Prompt engineering, then safety and alignment
Questions we're leaving for later:
- Jailbreaking: How do users bypass safety training? (Lecture 13)
- Whose values? Who decides what's "helpful" or "harmless"? (Lecture 14)
- Safety and alignment: How do we prevent harmful outputs? (Lecture 14)
- Reward hacking: How do models exploit reward models? (Lecture 14)
Summary
1. Pre-trained models need post-training to be useful assistants
- Base models complete text, don't follow instructions
- Post-training teaches them to be helpful, conversational
2. Post-training pipeline: SFT, collect human preferences, then PPO or DPO
- Supervised fine-tuning (SFT): supervised learning on demonstrations
- Collecting preferences: humans rank model outputs (shared step for both methods)
- PPO or DPO: two approaches to optimize the LLM using those preferences
3. Easier to judge than create
- Human rankings are faster and more consistent than writing responses
- This insight enables both approaches to scale
4. DPO simplifies RLHF - no separate reward model needed
- Train directly on (prompt, chosen, rejected) preference pairs
- Now the default approach for most open-source models
5. Constitutional AI offers another alternative
- Use explicit principles instead of implicit preferences
- AI helps evaluate AI, more scalable
- Different philosophy: encode values vs learn from behavior
6. Evaluation is hard
- Benchmarks help but don't capture everything
- Real-world evaluation (human studies, A/B tests) essential
- "Helpful, honest, harmless" is still vague