Lecture 8 - Decoding Strategies & Exam 1 Review
Welcome back!
Last time: Full transformer architecture - encoder blocks, decoder blocks, data flow
Today: Decoding strategies (40 min) + Exam 1 review (30 min)
Why this matters: You know how transformers produce probabilities. So how do we pick the next token?
Ice breaker
Ice breaker
When you use ChatGPT, have you noticed it gives different responses to the same prompt?
Any notable inconsistencies?
Agenda for today
Part A: Decoding Strategies (45 min)
- How transformers generate text
- Decoding algs: greedy, temp sampling, top-k, nucleus
- Beam search
Part B: Exam 1 Review (25 min)
- What's on the exam
- Example questions and practice
Part A: Text Generation & Decoding Strategies
Connecting to yesterday
Yesterday: Full transformer architecture - encoder, decoder, all the building blocks
Remember the final step? Decoder outputs a probability distribution over the entire vocabulary (~50k tokens)
[Decoder] -> Linear layer -> Softmax -> Probabilities over vocabulary
We have probabilities... now what? How do we actually pick the next token?
Example: Model output distribution
# After processing "The future of AI"
# Model outputs probabilities for next token:
probabilities = {
"is": 0.25,
"will": 0.20,
"lies": 0.15,
"looks": 0.08,
"seems": 0.07,
"remains": 0.05,
... ... # 50,000 more tokens
}
How do we pick the next token? What ideas do you have?
Strategy 1: Greedy Decoding
Always pick the highest probability token
next_token = argmax(probabilities)
# Result: "is" (probability 0.25)
Properties:
- Deterministic: same input, same output every time
- Safe, predictable
- Often boring, repetitive
- Can get stuck in loops
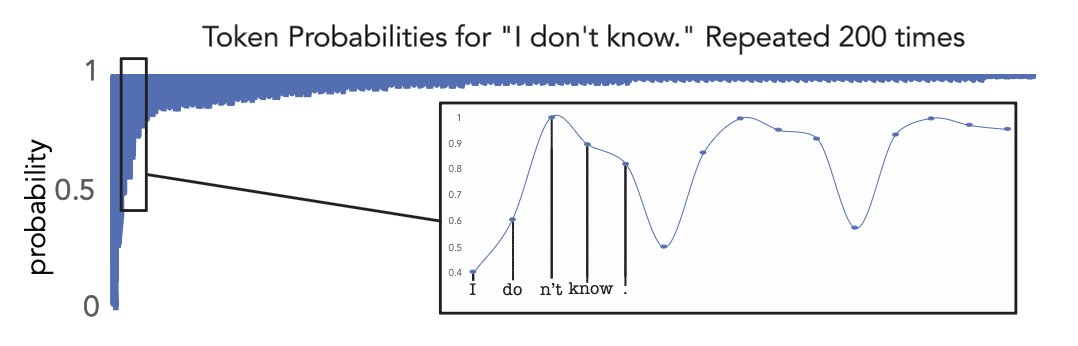
When to use greedy decoding
Good for:
- Factual question answering
- Translation (want accuracy, not creativity)
- Tasks where consistency matters
Bad for:
- Creative writing
- Brainstorming
- Open-ended conversation
Strategy 2: Sampling with Temperature
Sample from the probability distribution
Instead of always picking "is" (0.25 prob), sometimes pick "will" (0.20 prob) or "lies" (0.15 prob).
Temperature parameter controls randomness:
# Low temperature (0.1): nearly greedy
probabilities = [0.8, 0.15, 0.03, 0.02, ...]
# Medium temperature (0.7): balanced
probabilities = [0.4, 0.25, 0.15, 0.12, ...]
# High temperature (1.5): very random
probabilities = [0.22, 0.21, 0.19, 0.17, ...]
How temperature works
Temperature divides the logits before softmax:
- = raw logit for token
- = temperature
What this does:
- Low (e.g. 0.2): divides by a small number, so differences between logits get amplified. The top token dominates.
- : standard softmax, no change
- High (e.g. 1.5): divides by a large number, so logits get compressed. Distribution flattens out.
At the extremes:
- = greedy (always pick the top token)
- = uniform random
Intuition for temperature
Low temperature (toward 0): Sharpens the distribution. Top token dominates. Safe, repetitive.
High temperature (above 1): Flattens the distribution. More tokens get a real chance. Creative, unpredictable.
: The model's learned distribution, unmodified.
We'll see concrete examples and practical ranges in the demo at the end.
Strategy 3: Top-k Sampling
Problem with pure sampling: Occasionally picks very low-probability tokens (nonsense)
Solution: Only sample from the k most likely tokens
# Top-k = 5
filtered = {
"is": 0.25, # Keep
"will": 0.20, # Keep
"lies": 0.15, # Keep
"looks": 0.08, # Keep
"seems": 0.07, # Keep
# Everything else: ignored
}
# Renormalize and sample from these 5
Typical k values: 10-50
Top-k: Fixed budget
How it works:
- Sort all tokens by probability (highest first)
- Keep only top k tokens
- Set all other probabilities to 0
- Renormalize remaining probabilities
- Sample with temperature
Trade-off:
- Prevents nonsense
- But k is fixed, so sometimes too restrictive, sometimes too loose
Strategy 4: Top-p (Nucleus) Sampling
Better idea: Adapt the cutoff based on the distribution
Top-p (nucleus sampling): Keep smallest set of tokens with cumulative probability ≥ p
# Top-p = 0.9: keep tokens until cumulative prob >= 0.9
"is": 0.25 (cumulative: 0.25) -- keep
"will": 0.20 (cumulative: 0.45) -- keep
"lies": 0.15 (cumulative: 0.60) -- keep
"looks": 0.08 (cumulative: 0.68) -- keep
"seems": 0.07 (cumulative: 0.75) -- keep
"remains": 0.05 (cumulative: 0.80) -- keep
"could": 0.04 (cumulative: 0.84) -- keep
"has": 0.03 (cumulative: 0.87) -- keep
"was": 0.03 (cumulative: 0.90) -- STOP, reached 90%
"becomes": 0.02 (cumulative: 0.92) -- filtered out
Typical p values: 0.9, 0.95
Top-k vs Top-p
Top-k (fixed budget):
- Always keeps exactly k tokens
- Doesn't adapt to distribution shape
- Can be too restrictive or too loose
Top-p (nucleus - adaptive):
- Keeps variable number of tokens
- Adapts to model confidence
- Generally better performance
Strategy 5: Beam Search
Completely different approach: Keep multiple hypotheses
Instead of committing to one token at a time, explore multiple paths simultaneously.
Beam width (k): Number of hypotheses to track
Beam search example
Prompt: "The cat"
Step 1: Generate k=3 best next tokens
Hypothesis 1: "The cat sat" (score: -2.1)
Hypothesis 2: "The cat was" (score: -2.3)
Hypothesis 3: "The cat is" (score: -2.5)
Step 2: For EACH hypothesis, generate k=3 next tokens (9 candidates total)
From H1: "The cat sat on" (score: -3.2)
"The cat sat down" (score: -3.4)
"The cat sat there" (score: -3.6)
From H2: "The cat was sitting" (score: -3.8)
"The cat was black" (score: -4.0)
...
Step 3: Keep only the top k=3 from ALL 9 candidates, discard the rest
Kept: "The cat sat on" (score: -3.2)
"The cat sat down" (score: -3.4)
"The cat sat there" (score: -3.6)
Discarded: "The cat was sitting" (-3.8), "The cat was black" (-4.0), ...
Then repeat from Step 2 with these 3 survivors. Continue until done.
Beam search: Visual
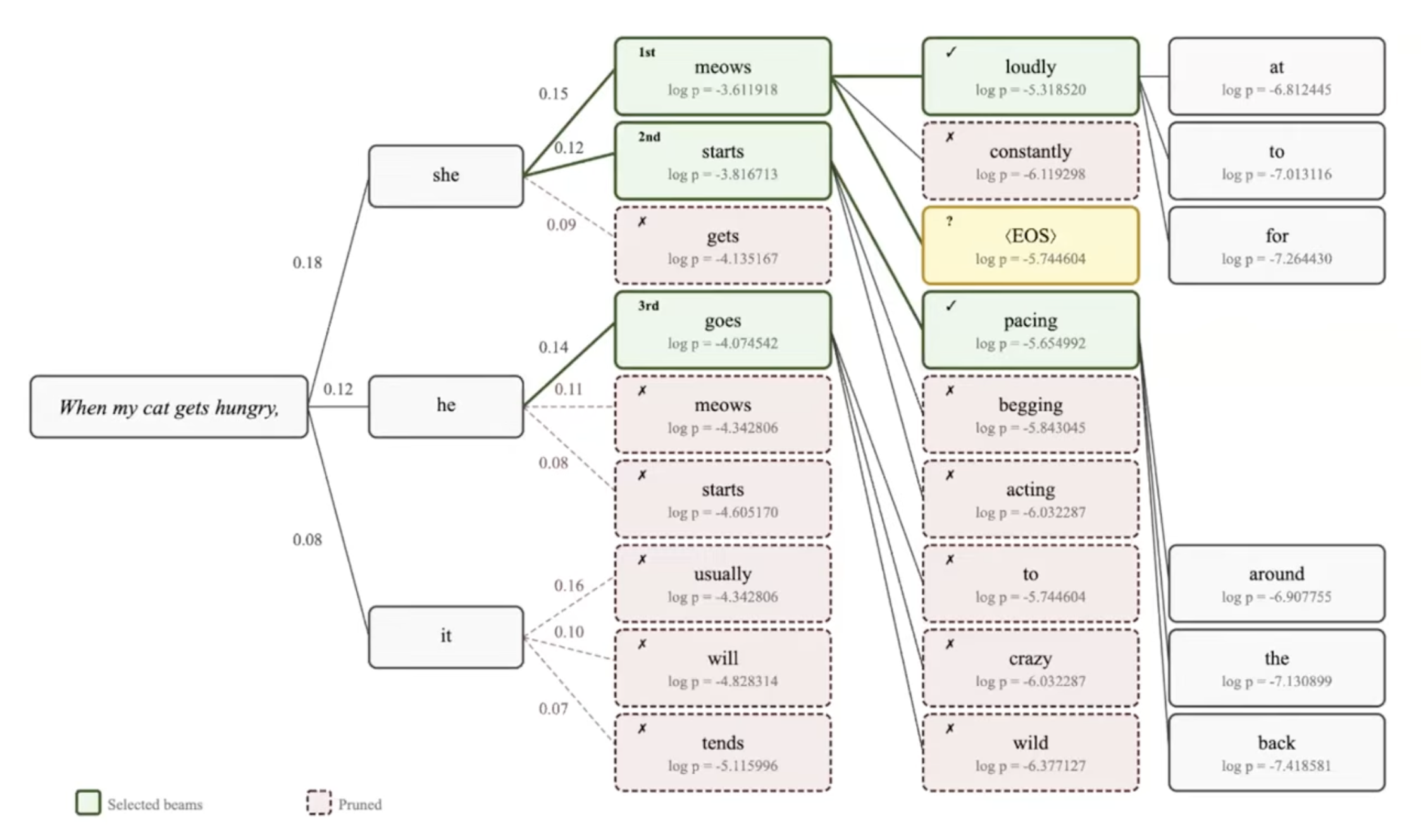
Beam search explores a tree, but only keeps the k best paths at each level
Beam search properties
One main parameter: beam width k
At each step, every beam proposes ALL possible next tokens (k × |vocab| candidates). We score them all and keep only the top k. Pruning happens at every step, not after some depth.
Advantages:
- Explores multiple paths (not trapped by early mistakes)
- Better quality than greedy for many tasks
- Good for translation, summarization
Disadvantages:
- Slower than sampling (k times more compute per step)
- Less diverse outputs (mode-seeking behavior)
- Can produce generic, safe text
Typical beam width: k = 3-5 for most tasks. Bigger k = better quality but diminishing returns past ~10.
Beam search vs sampling
| Aspect | Beam Search | Sampling |
|---|---|---|
| Goal | Find high-probability sequence | Generate diverse outputs |
| Speed | Slower (k times greedy) | Fast (single path) |
| Diversity | Low (similar beams) | High (random choices) |
| Quality | High for factual tasks | Variable (depends on temp) |
| Use for | Translation, summarization | Chat, creative writing |
Think-pair-share: Choose your settings
Scenario: You're building two different applications:
- A customer service chatbot for a bank
- A creative writing assistant for novelists
Turn to your neighbor (2 min):
- What temperature would you use for each?
- Would you use top-p, top-k, or neither?
- Why?
Research: "Too probable" text
Surprising finding from Holtzman et al. (2020):
Beam search text is more probable than human-written text, token by token. But it sounds worse. Why?
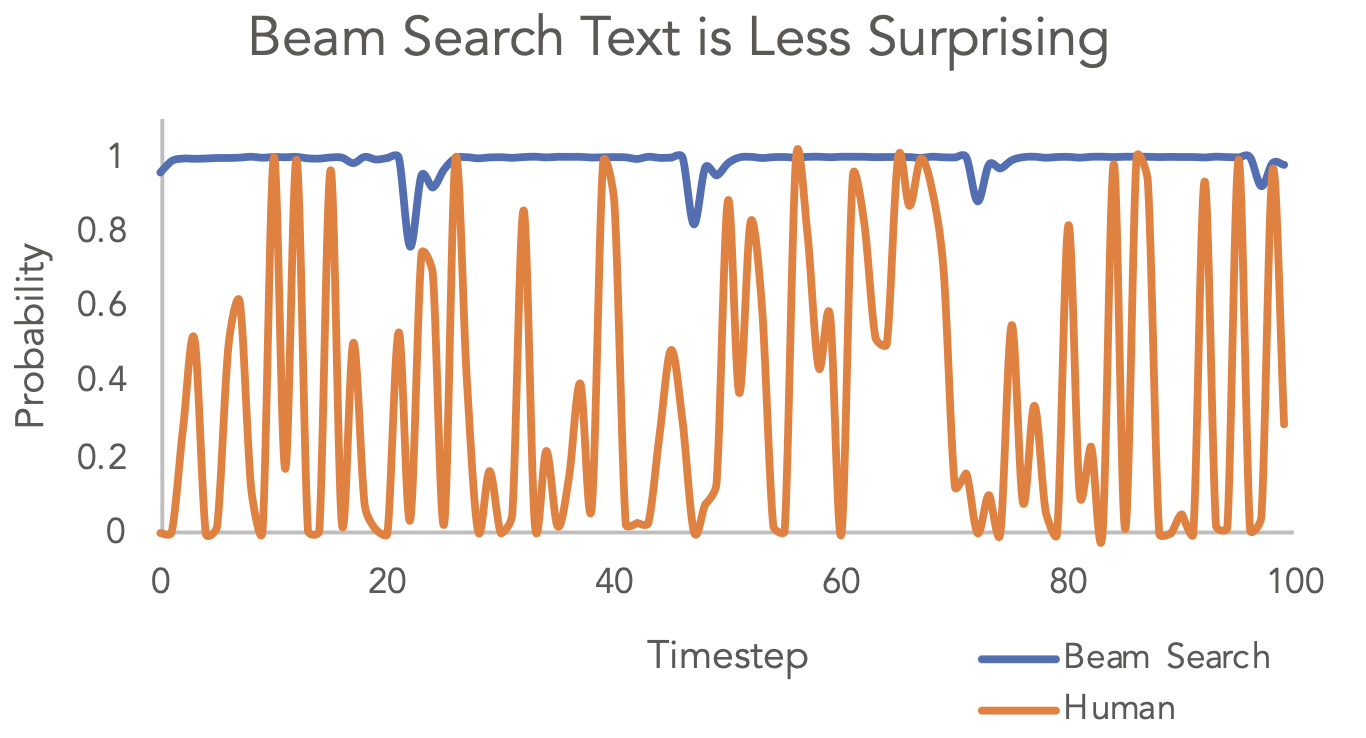
Human language is naturally surprising. We don't always pick the most likely word - we vary our word choice, take unexpected turns, add color. Beam search strips all that out.
This is why nucleus sampling was invented. It lets the model be surprising in the same way humans are.
One more practical trick: Repetition penalty
Problem: Even with sampling, models sometimes loop
You can’t know what it’s like to lose your sister. You can’t know what it’s like to lose your sister and not lose your sister. You can’t know what it’s like to lose your sister and still be with your sister. You can’t know what it’s like to lose your sister and still be alive. You can’t know what it’s like to lose your sister and know she is dead. You can’t know what it’s like to lose your sister and know she is dead, and yet still see her. You can’t know what it’s like to lose your sister and know she is dead, and yet still see her.
I’ve turned the space station into a spaceship. I’m a ghost, and I’m in a spaceship, and I’m hurtling through the universe, and I’m traveling forward, and I’m traveling backward, and I’m traveling sideways, and I’m traveling nowhere. I’m hurtling through the universe, and I’m a ghost, and I’m in a spaceship, and I’m hurtling through the universe, and I’m a ghost, and I’m in a spaceship, and I’m hurtling through the universe, and I’m a ghost, and I’m in a spaceship, and I’m hurtling through the universe, and I’m a ghost, and I’m in a spaceship, and I’m...
Fix: Repetition penalty. Reduce the probability of tokens that already appeared.
repetition_penalty> 1.0: penalize repeated tokens (1.2 is a common starting point)- OpenAI splits this into
frequency_penalty(how often it appeared) andpresence_penalty(whether it appeared at all)
Demo: Same prompt, different strategies
Prompt: "Write a story about a robot learning to paint"
Greedy:
The robot was designed to paint. It started by painting simple shapes
and gradually improved its technique. After many hours of practice...
Temperature = 1.0:
R0-B1T stared at the canvas, its optical sensors processing the swirls
of color in ways no human could understand. Paint was... fascinating...
Beam search (k=5):
The robot began its painting lessons with basic exercises. Through
careful observation and practice, it developed a unique artistic style...
Greedy and beam = safe, polished. High temp = creative, surprising.
Practical advice for projects
Temperature ranges:
| Range | Behavior | Good for |
|---|---|---|
| 0.0-0.3 | Focused, predictable | Factual Q&A, code generation, structured output |
| 0.5-0.8 | Balanced | Chatbots, general conversation |
| 0.9-1.5+ | Creative, unpredictable | Creative writing, brainstorming, poetry |
Default for most tasks: temperature 0.7 + top-p 0.9-0.95
Skip beam search unless you need maximum quality (translation, summarization).
Experiment. These are starting points, not rules.
Try it yourself (if time allows / return at the end)
Claude Temperature Effects Demo (https://claude.ai/public/artifacts/ab5532d8-7d61-4a98-acec-5cc4236f0d74)
- Quickly see responses at low/medium/high temperatures
OpenAI Playground (platform.openai.com/playground)
- PAID accounts only
- Adjust temperature and top-p with sliders
- See output change in real time
- Best way to build intuition for these parameters
FREE - HuggingFace Text Generation (huggingface.co/spaces)
- Open models (GPT-2, Llama, Mistral, etc.)
- Exposes all parameters: temperature, top-k, top-p, repetition penalty, beam search
- Free, no API key needed
Summary of Part A
- Transformers output probabilities, we choose tokens
- Greedy = deterministic, sampling = random
- Temperature controls creativity (0=boring, 1+=creative)
- Top-p better than top-k (adapts to distribution)
- Beam search = quality but generic, sampling = diverse
You'll use these settings in every project.
Part B: Exam 1 Review (30 min)
Exam 1 - Monday, Feb 23
Format:
- 75 minutes, closed-book, closed-notes, no devices
- Short answer, conceptual questions, one drawing question
- Five sections, 20 points each, 100 points total
Exam 1 - Monday, Feb 23
Format:
- 75 minutes, closed-book, closed-notes, no devices
- Short answer, conceptual questions, one drawing question
- Five sections, 20 points each, 100 points total
- Focus on conceptual understanding. Can you explain WHY, not just WHAT?
Oral redo: After grades come back, you can redo one section of your choice in a conversation with me. Details to follow.
The five sections
| Section | Topic | Points |
|---|---|---|
| 1 | Text Representation | 20 |
| 2 | Attention Mechanisms | 20 |
| 3 | Transformer Components | 20 |
| 4 | Decoder & Generation | 20 |
| 5 | Responsible AI | 20 |
What's NOT on the exam
- Backpropagation calculations or chain rule
- Specific code or API syntax
- Exact formulas for positional encoding, softmax, temperature
- Numerical computations (no calculator needed)
Section 1: Text Representation
- Why BPE over word-level or character-level
- Walk through a BPE merge step
- Distributional hypothesis; how Word2Vec uses it
- Skip-gram: what's input, what's predicted
- One-vector-per-word limitation; how transformers fix it
- Tokenization effects on cost, fairness, multilingual performance
Section 2: Attention Mechanisms
- The bottleneck problem and how attention solves it
- Roles of Query, Key, Value (analogy welcome)
- Why scale by ; what goes wrong without it
- Self-attention vs cross-attention: where do Q, K, V come from?
- Trace dimensions: , , , shape of
- What attention weights represent
Section 3: Transformer Components
You will draw multi-head attention from scratch:
- Projection matrices (, , ), attention formula, multiple heads, concatenation,
Also:
- Why positional encoding is necessary
- What residual connections and layer norm do
- FFN's role vs attention's role
- Learned (training) vs computed (forward pass)
Section 4: Decoder & Generation
- Label the three types of attention in a transformer diagram
- Why masking; when needed vs not
- Autoregressive generation: what feeds back into the decoder
- Training vs inference in the decoder
- Decoding strategies: greedy, temperature, top-p, beam search
- Recommend and justify settings for a given application
Section 5: Responsible AI
- Trace the bias pipeline: real-world inequality to model outputs
- Concrete examples of bias causing harm
- Why "just remove bias from data" isn't simple
- Risks of using AI-generated code without understanding it
- How the bias pipeline applies to coding tools too
- What responsible AI use looks like in practice
Practice Problem Bank
Work with a partner. ~15 minutes. We'll go over answers together.
These are similar in style and difficulty to exam questions.
Practice: Text Representation
(a) Given this corpus, what's the first BPE merge?
Corpus: "hug hug hug hugs bugs"
Character vocabulary: h, u, g, s, b
(b) The word "spring" can mean a season, a water source, or a metal coil. Why is this a problem for Word2Vec, and how do transformers handle it differently?
Practice: Attention & Dimensions
A transformer has , heads, input sequence of 8 tokens.
(a) What is ?
(b) What are the dimensions of Q and K for a single head?
(c) What are the dimensions of ? What does each entry represent?
(d) What goes wrong with attention scores if we skip the scaling?
Practice: Transformer Components
Draw it (3 min, from memory, then compare with your partner):
Draw the multi-head attention mechanism. Include:
- How Q, K, V are produced
- The attention formula
- Multiple heads and how they combine
- The output projection
Also discuss: Name two things that are learned during training and two things that are computed during the forward pass.
Practice: Label the Transformer
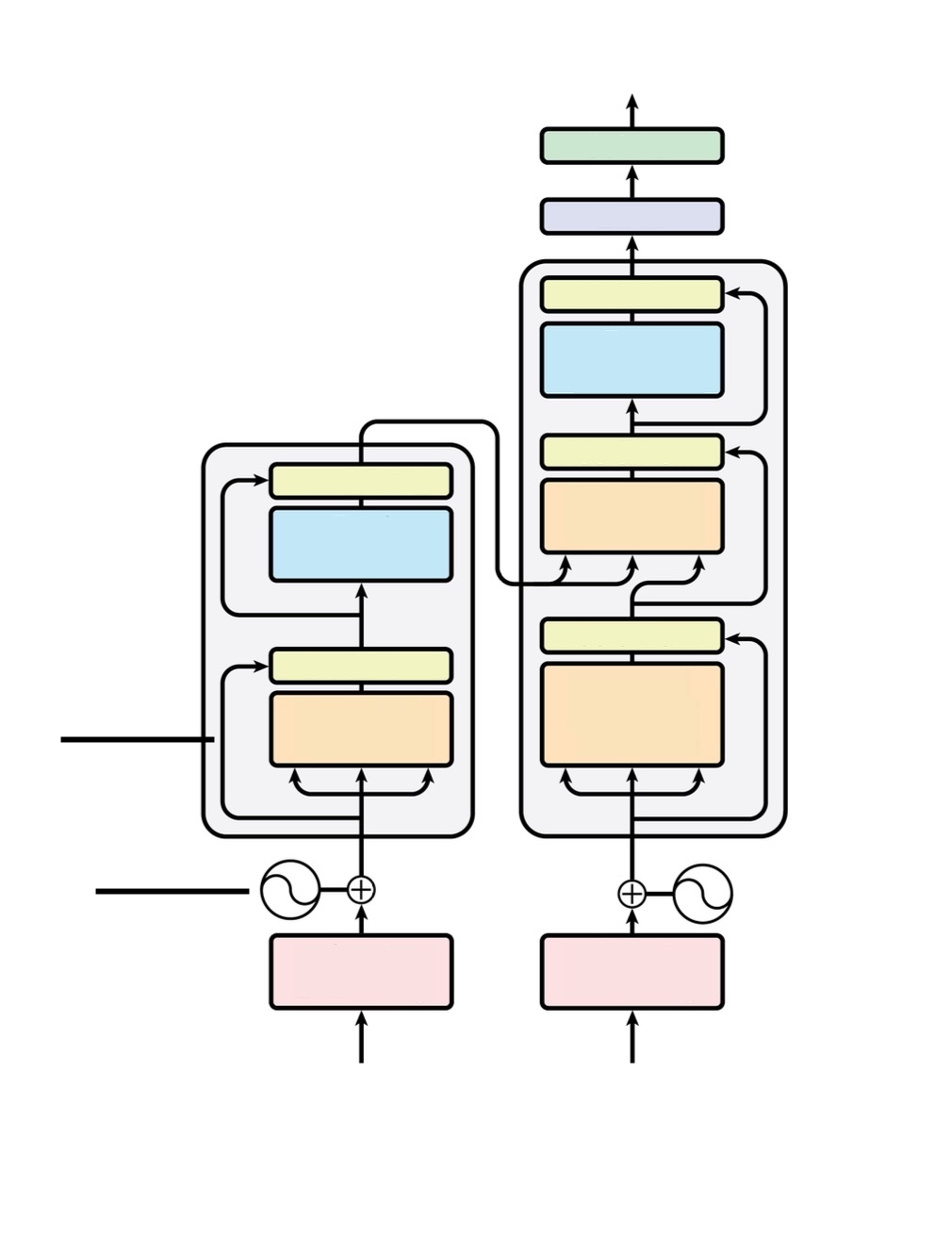
Call out answers as we go:
- Which side is the encoder? Which is the decoder? How can you tell?
- Label every colored box (what component does each one represent?)
- What are the curving arrows around each sublayer?
- Where does information flow from encoder to decoder?
- What do the two symbols at the bottom represent?
- What are the two boxes at the very top of the decoder?
Practice: Decoder & Masking
(a) Name the three types of attention in a full encoder-decoder transformer. For each: where does it live, and where do Q, K, V come from?
(b) The decoder uses masked self-attention during training, but generates one token at a time during inference. Why is masking needed during training but not inference?
Practice: Decoding Strategies
You're building two apps:
- App A: A legal contract summarizer
- App B: A D&D dungeon master that generates NPC dialogue
For each: recommend a temperature range, whether to use top-p or beam search, and justify in one sentence.
Practice: Responsible AI
(a) A classmate says: "AI-generated code is safe because it comes from StackOverflow answers that were already reviewed by the community." Give two reasons this reasoning is flawed.
(b) Give one concrete example of how the bias pipeline applies to AI coding tools specifically (not just text generation).
Your questions?
What concepts are still confusing?
What topics should we clarify?
Any questions about exam format or logistics?
Final reminders
Before Monday:
- Practice drawing the attention mechanism from memory
- Review lecture slides (focus on concepts, not details)
- Skim your weekly reflections (what stuck with you?)
- Full study guide on Piazza after today's class
Portfolio Piece 1 due Friday (Feb 20) - don't forget!
Office hours available through the rest of the week
You've got this. The exam tests understanding, not memorization. If you've engaged with the material and can explain WHY things work the way they do, you'll do well.
See you Monday!