Lecture 11 - The LLM Landscape: Survey of Models
Welcome back!
Last time: Post-training and RLHF - making models helpful
Today: Navigating the LLM landscape - which model for which task?
Looking ahead: Next we dive into applications (fine-tuning, prompting, RAG), agents
Ice breaker: Straw poll
Quick poll: Which LLMs have you used?
- ChatGPT (GPT-3.5, GPT-4)
- Claude
- Gemini (formerly Bard)
- Open-source models (LLaMA, Mistral, etc.)
- Other
- None yet
Ice breaker: A harder question
Alan Turing (1950): If a machine can hold a text conversation that's indistinguishable from a human, we should say it "thinks."
Do you think any of the LLMs you just listed pass the Turing Test?
- A) Yes - I have (or could have) been fooled
- B) No - you can always tell
- C) Abstain - Depends who's asking / what the task is
- D) Objection - The test itself is flawed
Note: benchmarks try to answer this same question, and always imperfectly. We'll come back to this.
Mid-Semester Check-In
Mid-semester survey: thank you
Overall rating: 36 of 38 gave the course 4 or 5 out of 5
What came through clearly:
- The exam ran long, and many of you ran out of time
- Weekly lab + reflection together adds up
- Discussion sections can feel like solo work with a TA nearby
- Project scope and getting started is a top concern
- A "big picture" map of how everything connects would help
Changes for the second half
- All due dates move to Sunday
- No Portfolio Piece 2. Replaced by project milestones (graded completion-style, same as labs)
- Weeks 10 and 11 labs connect directly to your project work
- Project abstract due before Exam 2, so you know your direction going into it
- Nothing due exam week
- Exam 2: shorter, more fill-ins and fewer short-answer for more time to think
- Discussion sections: more structured walkthroughs, more time for questions (will pass the feedback on)
- All submissions go through Gradescope. Reflections and check-ins: enter text directly. Labs and project work: push to GitHub, submit the repo link on Gradescope.
- I'll try out posting lectures in advice so you can preview/print if you want and review right after, but I want to avoid this turning into folks reading in parallel on laptops (I also fiddle with lectures til the last minute so it might not be up to date)
New grading structure
Before break (35% of course grade)
| Weight | |
|---|---|
| Labs + Reflections | 5% |
| Portfolio Piece 1 | 5% |
| Midterm 1 | 20% |
| Participation | 5% |
After break (65% of course grade)
| Weight | |
|---|---|
| Completion-based tasks | 10% |
| Midterm 2 | 20% |
| Final Project | 30% |
| Participation | 5% |
Project milestones (replacing PP2)
All graded for completion.
| Due | Checkpoint | What |
|---|---|---|
| Sun Mar 29 | Project Ideation | 2-3 project ideas, teams confirmed |
| Sun Apr 12 | Abstract | 200-300 words: what you're building, with what data, how you'll evaluate |
| Sun Apr 19 | Readiness check | Data acquired, compute confirmed, repo initialized |
| Sun Apr 26 | Progress check-in | 300 words + link to repo showing work started |
What's staying
The screen-free policy Most of you like it. Some are neutral, some want to see it enforced more. If you have a note-taking system that needs a device, come talk to me.
Icebreakers Popular overall but limited value, I'll try to tighten timing.
The website, notesheets, and week guides You rated all of these very highly, with some helpful suggestions.
Agenda for today
- Foundation models
- Survey of model families
- The cutting edge: MoE and reasoning models
- Choosing the right model
Part 1: Foundation Models Philosophy
The old way: Task-specific models
Pre-2018 approach: Train a separate model for each task
- Sentiment analysis: train a sentiment model
- Translation: train a translation model
- Question answering: train a QA model
Problem: Expensive, data-hungry, learning doesn't transfer between tasks
The foundation model paradigm
New approach (2018+): Pre-train once on massive data, then adapt for many tasks
General language understanding transfers to specific tasks
Term: "Foundation model" (Stanford, 2021) - a model that serves as the foundation for many applications
Economic implications
Pre-training: $10M-$100M+ (once)
Fine-tuning: $100-$10,000 (per adaptation)
Prompting: Near-zero (just API calls)
Result: Centralization - few organizations can afford to pre-train, many can adapt
Open discussion: Implications of centralization
What are the pros and cons of only a few companies building foundation models?
Architectural foundations: A quick recap
| Architecture | Examples | Best For |
|---|---|---|
| Encoder-only | BERT, RoBERTa | Classification, embeddings - cheap and fast |
| Decoder-only | GPT, Claude, LLaMA | Generation, chat - dominates today |
| Encoder-decoder | T5, BART | Translation, summarization |
Most modern LLMs are decoder-only: scales well, one architecture for many tasks. Given enough parameters and data, decoder-only handles understanding and generation.
For classification tasks (spam, sentiment), encoder-only models like BERT are still widely used in production - no generation needed, and much cheaper.
Part 2: Survey of Model Families
A snapshot of the landscape
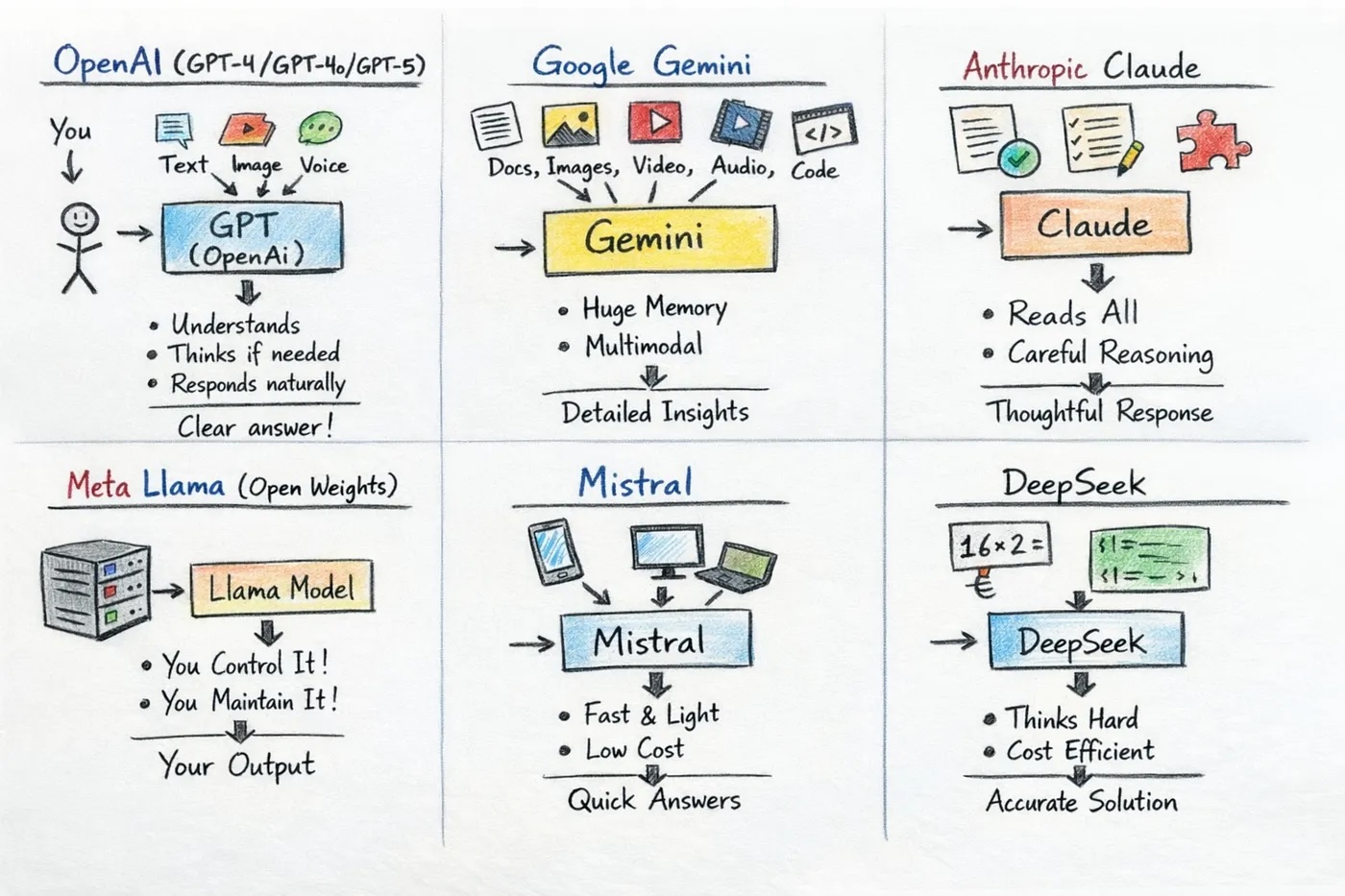
Source: Vamsi Sankarayogi
How the landscape is evolving
It changes every few months! So we want to learn the evaluation framework, not memorize specific models

Source: Oguz Ergin
GPT family (OpenAI)
Philosophy: Bet early that more compute + more data = smarter models.
- Closed source, API-first
- Backed by Microsoft ($13B+) and VCs, can afford to run at a loss
- Huge developer ecosystem; many tools default to OpenAI
- o-series models trade speed and cost for multi-step reasoning
- First-to-market advantage among consumers
- Current lineup: GPT-4o mini (fast/cheap), GPT-4o (standard), GPT-5 (flagship); o4-mini and o3 (reasoning - slow but powerful)
Strengths: Broad capabilities, strong reasoning, largest ecosystem
Weaknesses: Expensive, fully closed, data privacy concerns
Use cases: General-purpose assistant, complex reasoning, coding
Claude family (Anthropic)
Philosophy: Safety-first by design. Founded by ex-OpenAI researchers. Constitutional AI is their answer to RLHF issues.
- Backed by Amazon, Google
- Long context (200K tokens) as a deliberate differentiator
- Outputs tend to be less sycophantic
- More safety, fewer hallucinations
- Active in interpretability research
- Current lineup: Haiku 4.5 (fast/cheap), Sonnet 4.6 (balanced, most used), Opus 4.6 (most capable, most expensive)
Strengths: Long context, careful and honest outputs, strong coding and analysis
Weaknesses: More expensive, sometimes over-cautious
Use cases: Document analysis, research, nuanced writing, coding
Gemini family (Google)
Philosophy: Data advantages. Google has the search index, YouTube, Gmail - the largest training data pipeline in the world. Plus custom TPU hardware.
- 1M+ token context is a genuine differentiator (eg entire codebases, book-length docs)
- Native multimodal
- Deep integration with Google Workspace, Search, Android
- Rapidly iterating lineup; naming has been chaotic
- Current lineup: Gemini Flash (fast/cheap), Gemini Pro (standard), Gemini Ultra (most capable); current flagship is Gemini 3.1 Pro
Strengths: Extremely long context, multimodal, Google ecosystem integration
Weaknesses: Fast-changing lineup, uneven availability by region, product inconsistency
Use cases: Massive document analysis, multimodal tasks, Google ecosystem
LLaMA family (Meta)
Philosophy: Open weights as a business strategy, not charity.
- Zuckerberg believes open source wins long-term
- Massive compute budget (tens of thousands of GPUs)
- LLaMA weights are the base for thousands of fine-tuned community models
- MoE architecture in recent versions: frontier performance at fraction of the cost
- Current lineup: LLaMA 3.1 (8B / 70B / 405B - small/medium/large); LLaMA 4 Scout and Maverick (MoE variants, 17B active params with much larger total)
Strengths: Open weights, huge community ecosystem, multiple size options, customizable
Weaknesses: You host it yourself (or pay for API); less polished than commercial models
Use cases: Research, fine-tuning, privacy-sensitive apps, cost optimization
Mistral family (Mistral AI)
Philosophy: Small team, big efficiency. MoE architectures that get frontier-competitive performance at a fraction of the cost. Loudest open-weight voice in European AI policy.
- Strong advocates for open-weight models in EU regulation
- European company = GDPR compliance built in
- Mixtral's MoE design influenced the whole industry (Meta, Google followed)
- Far fewer resources than big tech, but arguably better efficiency per parameter
- Current lineup: Mistral Small (fast/cheap), Mistral Large (capable); Mistral 3 is their current open-weight frontier model
Strengths: Efficient MoE architectures, open weights, European data sovereignty
Weaknesses: Smaller company, fewer resources, smaller ecosystem than Meta/OpenAI
Use cases: Europe-focused deployments, efficient self-hosting, open-weight alternatives
Other labs you'll hear about
xAI / Grok (Elon Musk, 2023): Grok 3 (Feb 2025) competitive with frontier models; unique access to real-time X/Twitter data; generally less restricted outputs than other labs
Alibaba / Qwen (China, 2023): Qwen 2.5 series - strong open-weight models across many sizes, Apache 2.0 license, excellent multilingual and coding; widely used as a base for fine-tuned variants
DeepSeek (China, 2023): V3.2 and R1 - competitive open-weight models trained at remarkably low cost; more on this shortly
Zhipu AI / Z.ai (China, Tsinghua University, 2019): GLM series - strong Chinese-English bilingual models; GLM-4-32B (MIT license) matches GPT-4o on several benchmarks at a fraction of the size; GLM-Z1 is their reasoning model; also known for multimodal and agent research
Cohere (Canada, 2019): Command R series - enterprise-focused, optimized for RAG and tool use
ALSO - ByteDance!? (Seed), Moonshot (Kimi), Baidu (ERNIE), Amazon, NVIDIA...
The frontier isn't just the US anymore. Other labs are building competitive models, and they're often open-weight and cheaper.
Part 3: The Cutting Edge: MoE and Reasoning Models
Mixture-of-Experts (MoE): How it works
The problem: More parameters = better, but also more expensive to run
Every token has to pass through every layer even if most of them aren't "needed"
The idea: Replace each dense feed-forward layer with N "expert" sub-networks plus a router
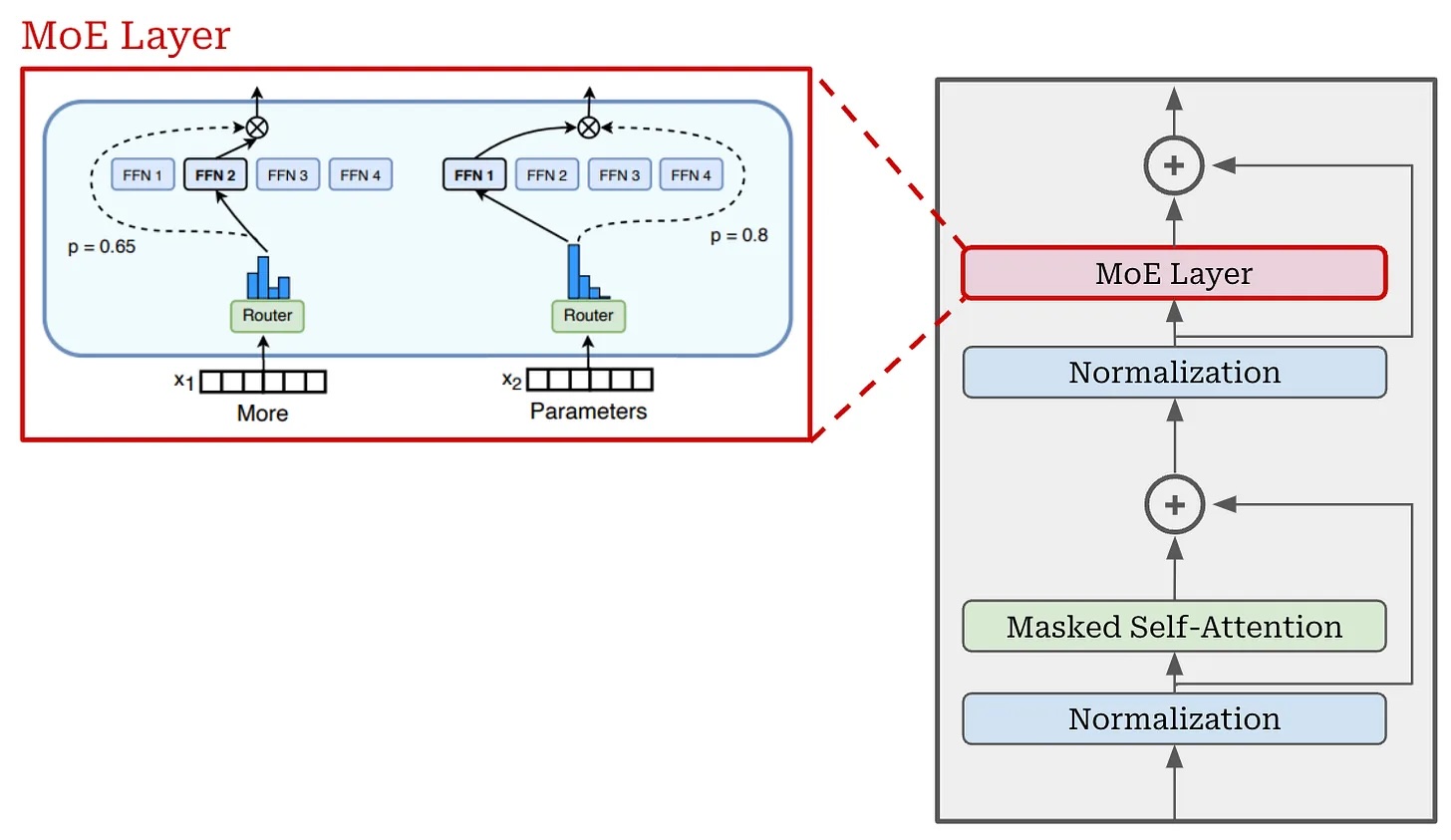
How it works:
- Router scores each token against all N experts
- Only the top 2-4 experts activate - the rest do no work
- Each token takes a different path through the network
Result: "Active" parameters << "total" parameters
- LLaMA 4 Maverick: 17B active / 400B total - runs at 17B cost, draws on 400B of learned knowledge
- Mixtral 8x7B: 12B active / 47B total - GPT-3.5-level quality at a fraction of the inference cost
DeepSeek: MoE in practice
DeepSeek V3 is a case study in how MoE enables frontier performance at a fraction of the cost.
V3 architecture: ~37B active / 671B total parameters - frontier-level knowledge, paid for with 37B worth of compute per token
Distilled versions: Take a large "teacher" model and train a smaller "student" to mimic it
- Teacher model was DeepSeek R1
- Student models were fine-tuned LLaMA and Qwen
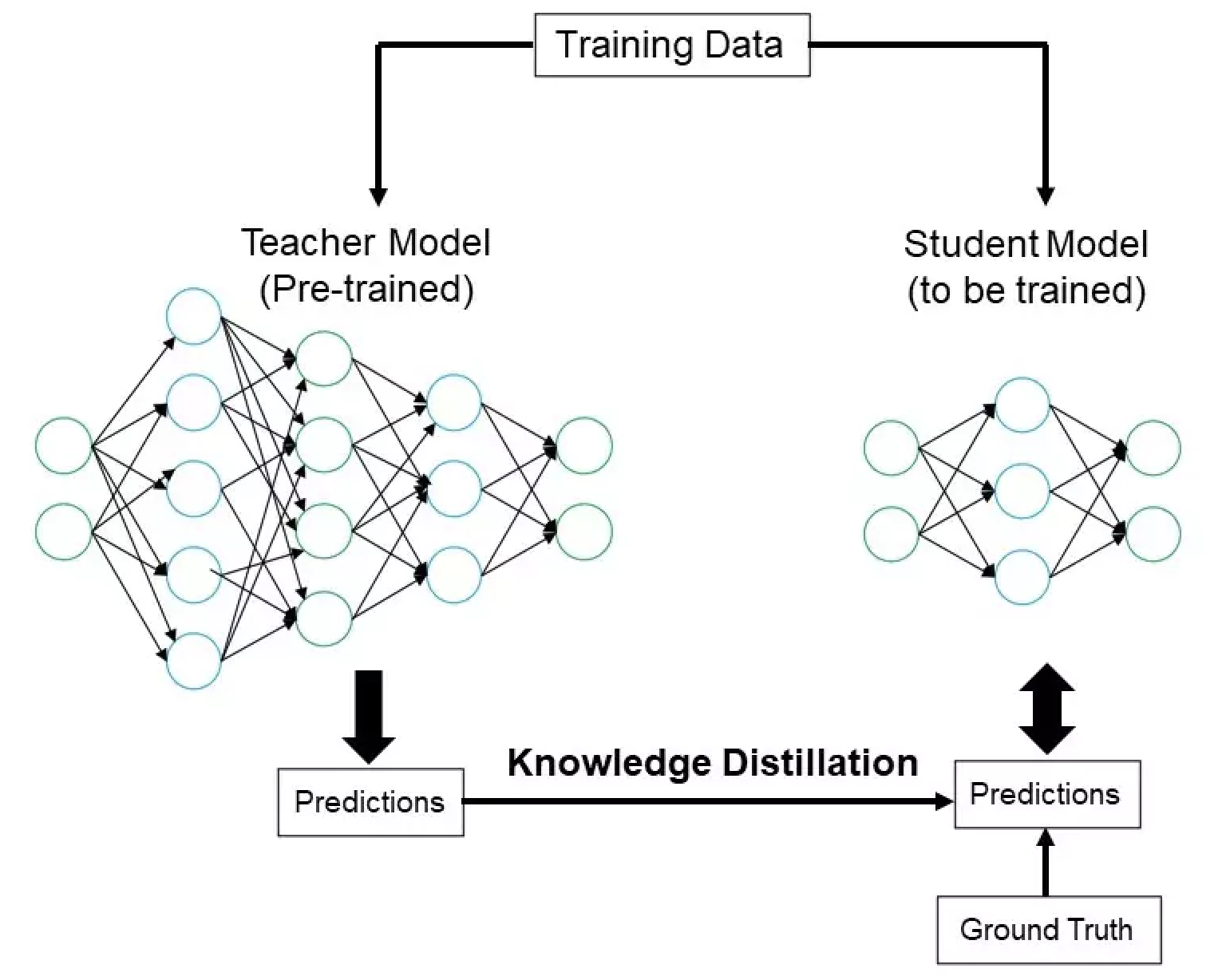
Why it matters: MoE + distillationlet a smaller team produce a model that matched o1 on math/science benchmarks.
A new category: Reasoning models
What changed in 2024-2025: Models that think before answering
Instead of immediately predicting the next token, they generate a hidden chain of thought first
- o1, o3, o4-mini (OpenAI, 2024-2025): First major reasoning models
- DeepSeek-R1 (Jan 2025): Open-source, MIT license, matched o1 on math/science
- Gemini 2.5 Pro (Mar 2025): "Thinking mode" - hit #1 on coding leaderboards
- Claude 3.7 Sonnet (Feb 2025): "Extended thinking" - can show reasoning steps
Tradeoff: Slower and more expensive, but significantly better on hard tasks
When to use: Complex math, science, multi-step code, anything where accuracy matters more than speed
Now (2026): Reasoning is integrated into most frontier models - GPT-5, Claude 4.x, Gemini 3
Reasoning models visualized
All credit to Maarten Grootendorst (unsurprisingly, Jay Alaamar's co-author)
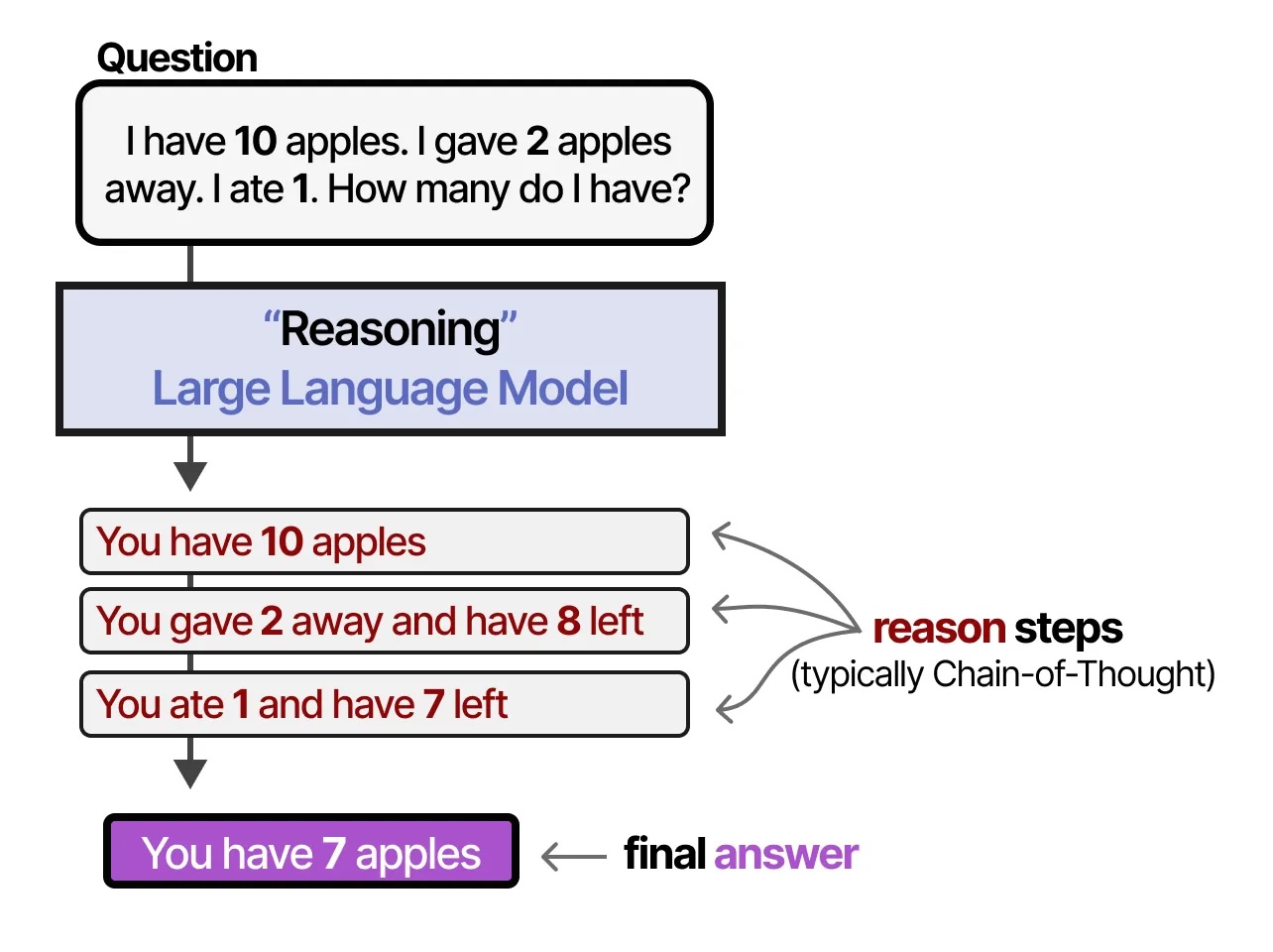
Reasoning models visualized
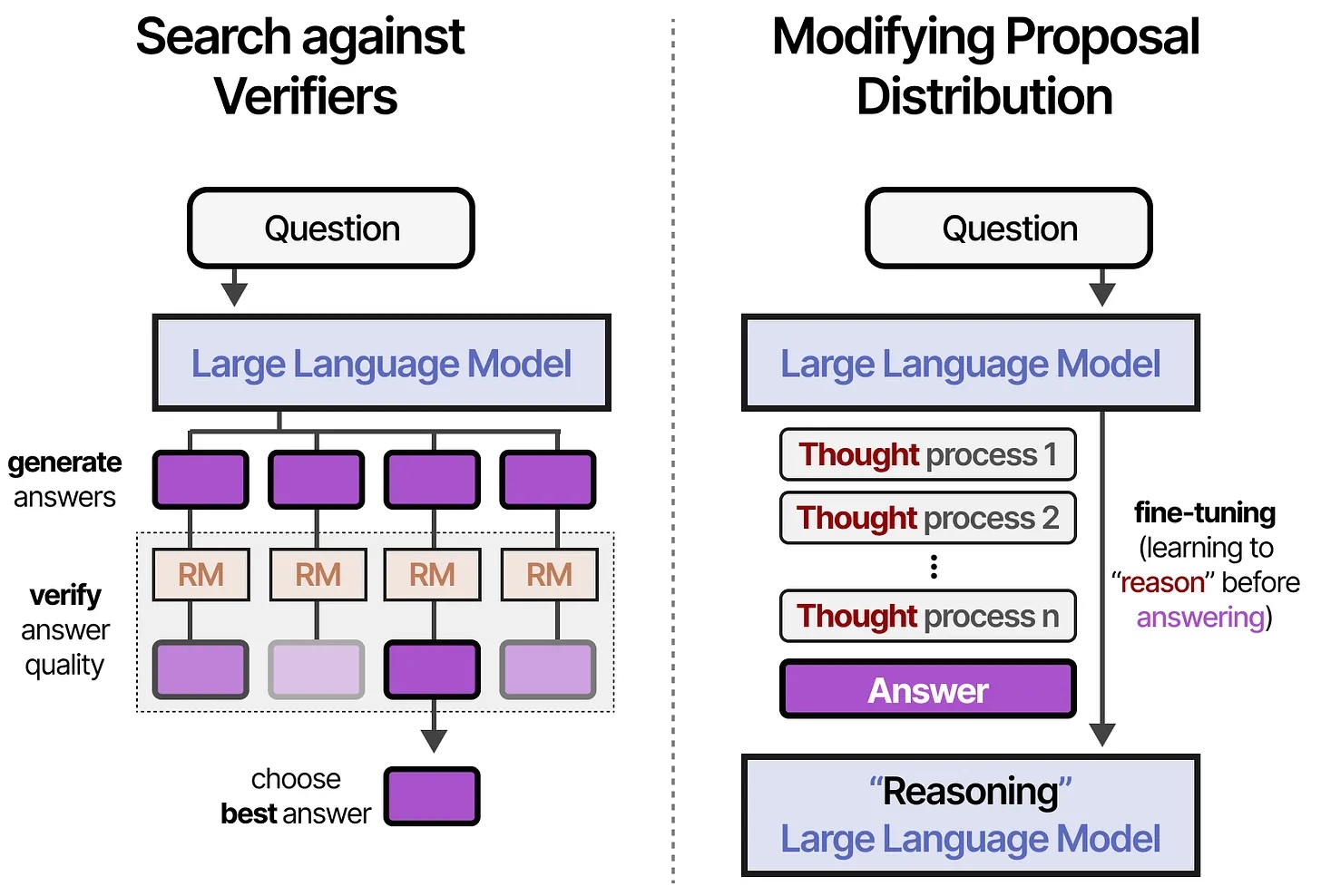
Reasoning models visualized
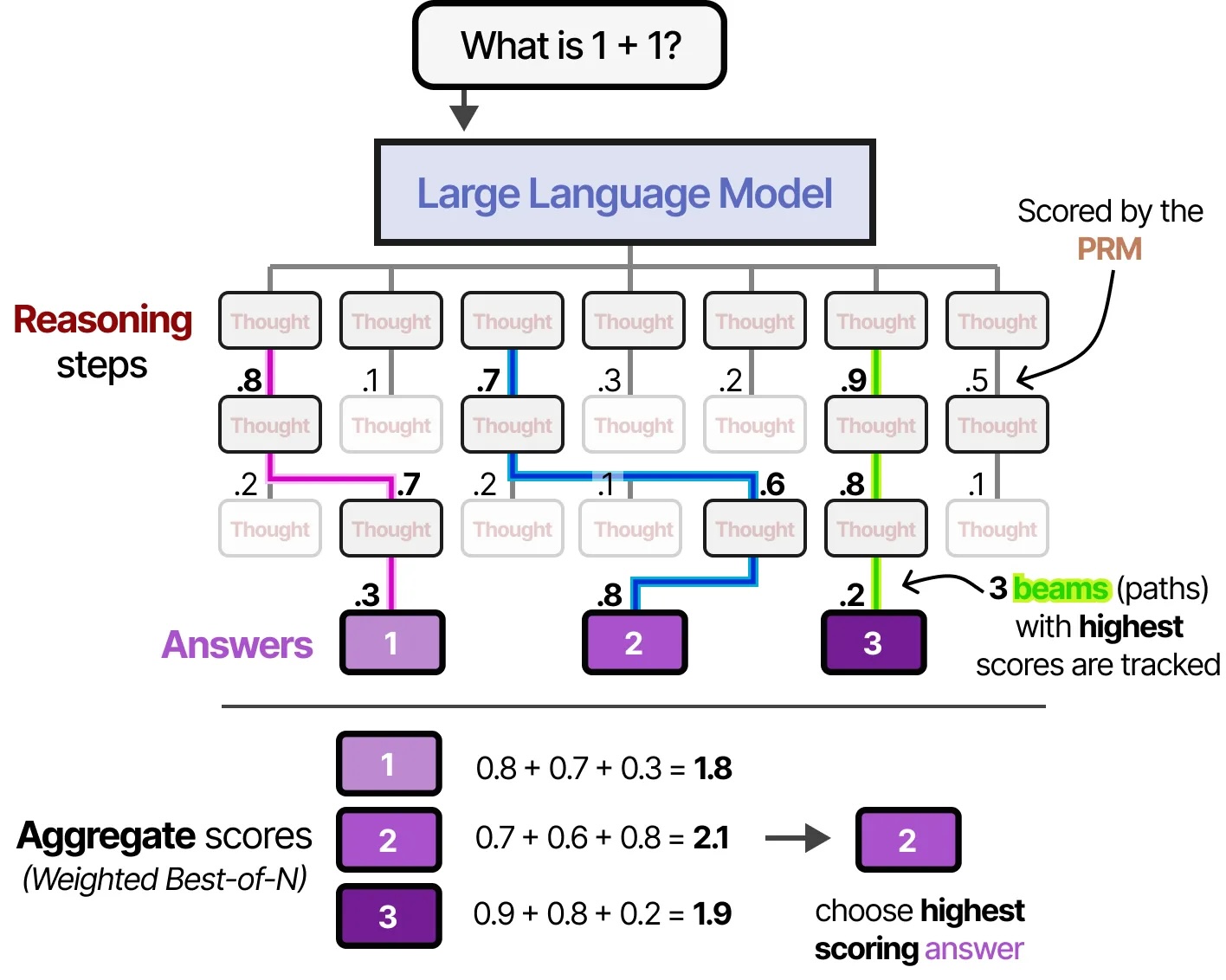
Reasoning models visualized
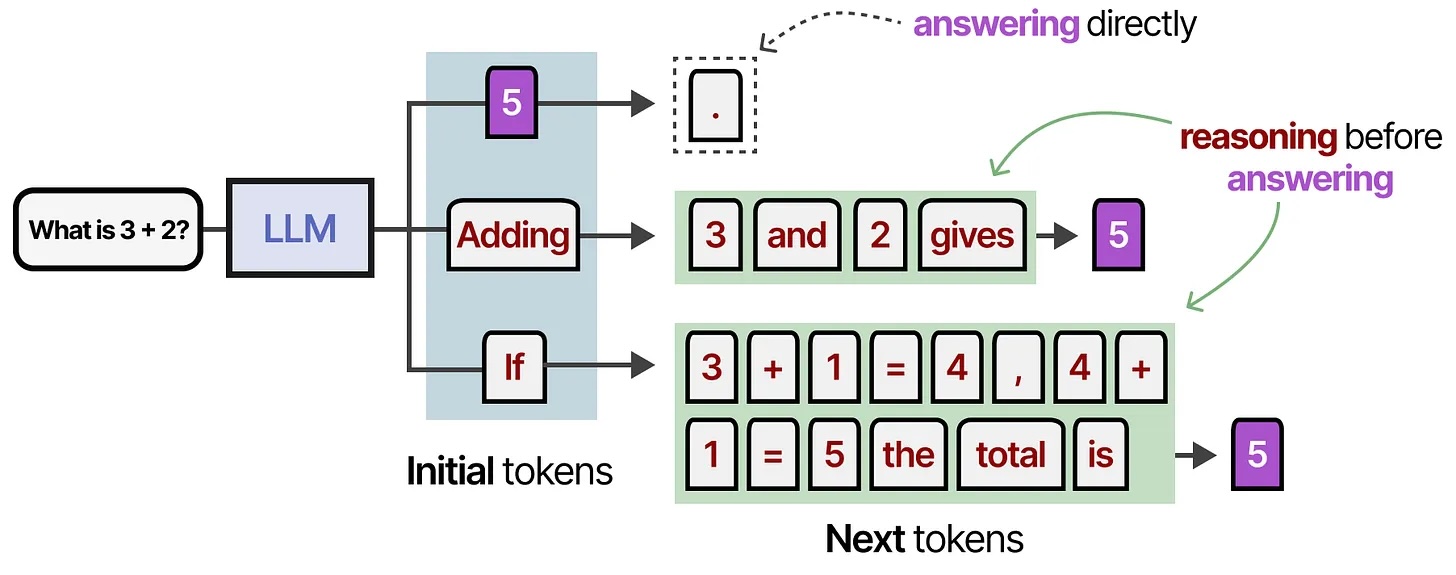
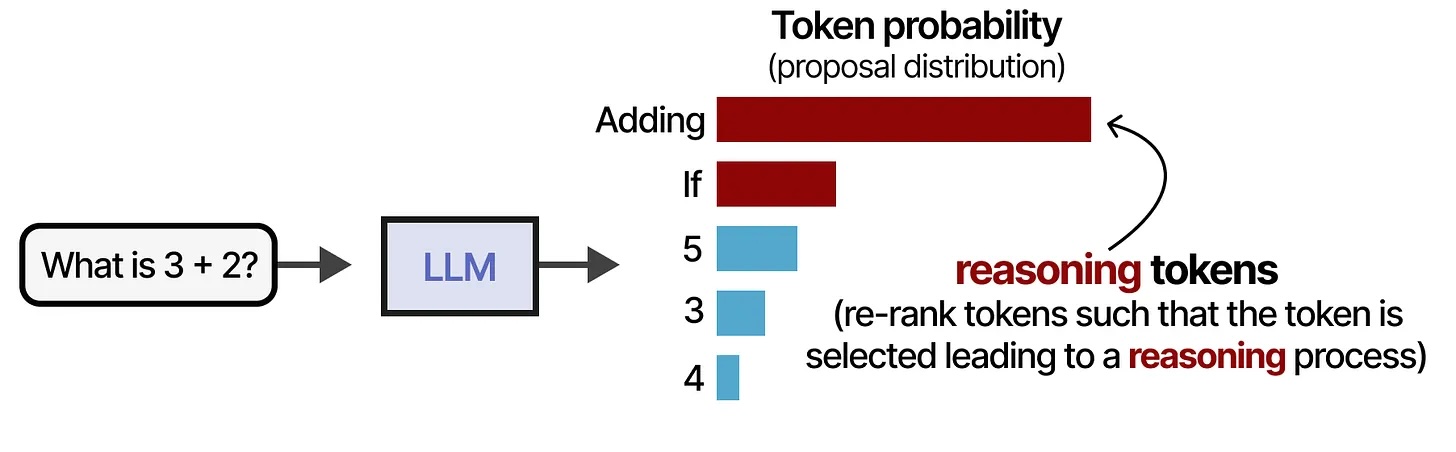
But reasoning isn't perfect

Part 4: Choosing the Right Model
Performance comparison
MMLU is nearly saturated - frontier models all score 88-92%, so it's not a useful signal anymore.
| Category | Benchmarks to watch | Leading models |
|---|---|---|
| Hard reasoning | GPQA Diamond (PhD science), AIME | o3, Gemini 3 Deep Think, Claude Opus 4.6 |
| Coding | SWE-bench Verified | GPT-5, Claude Sonnet 4.6, LLaMA 4 Maverick |
| Long context | NeedleInAHaystack, RULER | Gemini (1M+), Claude (200K+), LLaMA 4 Scout (10M!) |
| Cost-efficiency | Price per token | GPT-4o mini, small open models |
| Privacy | - | Any open-weight model on-prem |
| Overall | Chatbot Arena (blind votes) | Varies by task |
Rough tiers as of early 2026:
- Frontier: GPT-5, Claude Opus 4.6, Gemini 3.1 Pro
- Strong: Claude Sonnet 4.6, GPT-4o, Gemini 3 Pro
- Competitive open: LLaMA 4 Maverick, Mistral 3, DeepSeek-V3.2
- Efficient: LLaMA 4 Scout, Mistral Small
- Tiny: Llama 3.1 8B, Qwen 2.5 7B
There's no single "best" model - it depends on your needs!
What does "open" mean?
Spectrum of openness:
- Truly open: Model weights, training code, datasets (rare)
- Open weights: Weights available, but not training details (LLaMA, Mistral)
- Open API: Anyone can call it, but weights hidden (OpenAI, Anthropic)
- Closed: Nothing public
Most "open source" LLMs are actually "open weights"
Open vs. closed: trade-offs at a glance
| Open (LLaMA, Mistral) | Closed (GPT-5, Claude 4.x) | |
|---|---|---|
| Performance | Close to frontier on most tasks | State of the art, especially agentic |
| Cost | GPU infra + no per-token fees | Per-token pricing adds up |
| Privacy | Run on-prem, data stays local | Data goes to external servers |
| Customization | Fine-tune freely | Limited, via vendor options |
| Ease | Need GPUs + DevOps | Just call an API |
| Lock-in | None | Vendor-dependent |
| Safety | You own it | Built-in guardrails |
Is closed always better?
A striking finding from Epoch AI:
The performance gap between open and closed models on MMLU:
- End of 2023: 17.5 percentage points (closed far ahead)
- End of 2024: 0.3 percentage points (essentially tied)
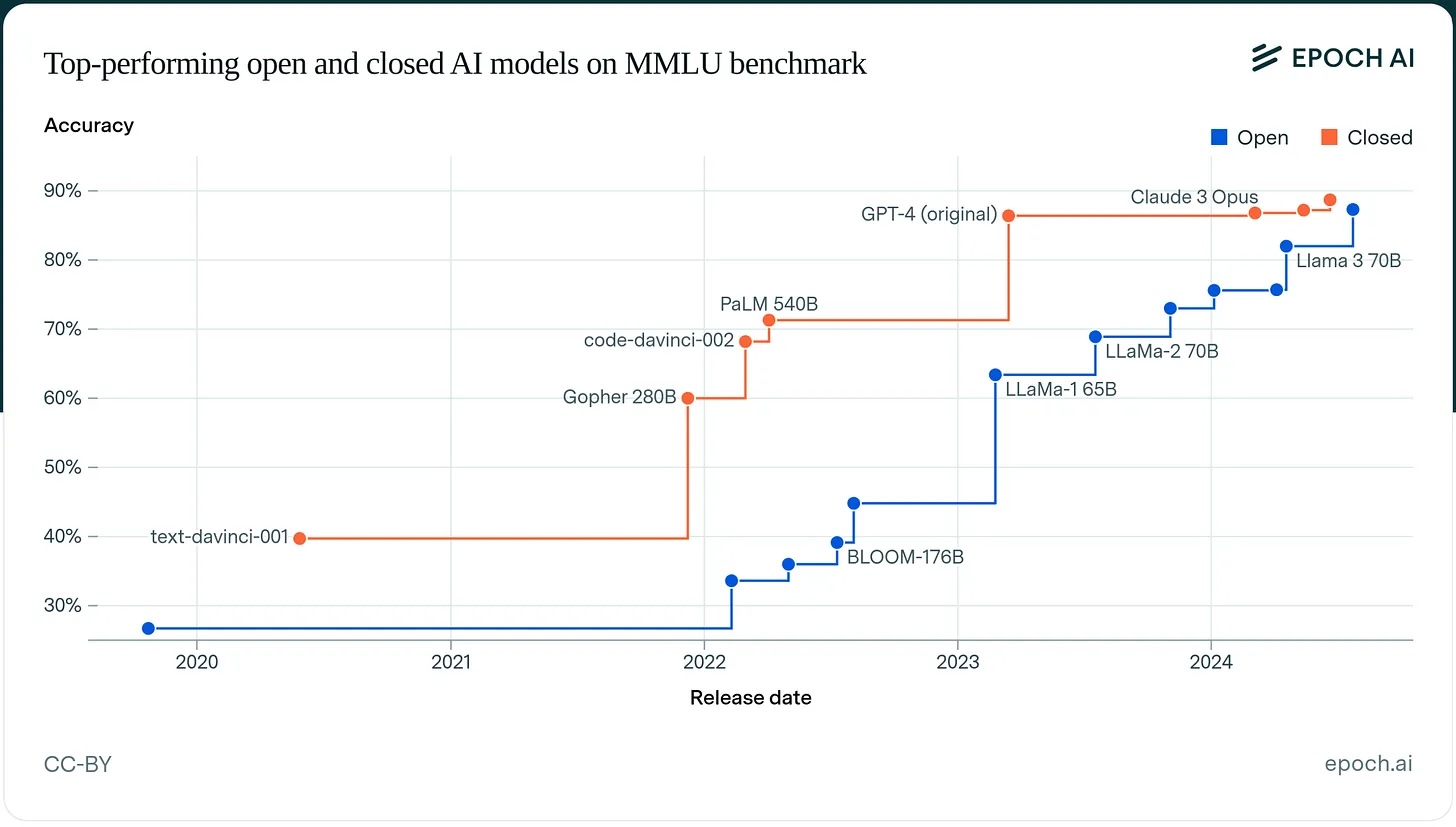
The remaining gap: Closed models still lead on agentic tasks and real-world coding. But for many applications, open models are close enough to matter.
Think-pair-share: When to use which?
Scenario: You're building a healthcare chatbot that handles sensitive patient data
Question: Open or closed model? Why?
Think-pair-share: Some thoughts
Arguments for open:
- HIPAA compliance - data privacy is critical
- Need to keep data on-premises
- Can fine-tune for medical terminology
- No ongoing costs per query
Arguments for closed:
- Better performance on medical questions
- Professional support and reliability
- Safety guardrails for medical advice
- Companies offer HIPAA-compliant options (e.g., Azure OpenAI)
License considerations
Not all "open" licenses are the same!
- MIT/Apache/BSD: Truly open, commercial use allowed
- GPL: "Copy-left" (all derivatives must be open-source)
- RAIL: Tries to enforce "responsible" AI use
- Llama2: Limited commercial use
- Creative Commons: Lots of variations, mostly bans commercial use
Always check the license before building on a model!
What's a model card?
Model card: Documentation about a model's capabilities, limitations, training, and intended use
Includes:
- Training data sources and curation
- Evaluation metrics and benchmarks
- Known limitations and biases
- Intended use cases and misuse potential
Why it matters: Users should know what they're working with!
Examples of model cards
Released by OpenAI alongside GPT-5 (60 pages)
Contents:
- Evaluation on 40+ benchmarks
- Red-teaming process and findings
- Safety mitigations (RLHF, rule-based filters)
- Known failure modes (hallucinations, biases)
Notable omissions: Parameter count, architecture details, training data sources, compute used - all withheld citing competitive concerns. Strong on safety disclosure, selective on everything else.
What model cards should include
Training details: Data sources, compute used, training process
Evaluation: Benchmark scores, human evaluations
Limitations: What it can't do, where it fails
Biases: Known unfairness or representation issues
Intended use: What it's designed for, what to avoid
Reality: Not all models provide this level of detail
The transparency spectrum
High: LLaMA 2/3/4, many Hugging Face models (architecture, training data, compute disclosed)
Medium: GPT-4/5 (detailed safety evals, but architecture and training data withheld); basic benchmarks, vague training details
Low: "We trained a model" (no details)
Question for you: How much transparency should be required?
EU AI Act and other regulations are starting to require more transparency. This will evolve.
Group activity: Model selection scenarios (10 min)
We'll break up into 8 groups with a count-off, each group gets two scenarios.
Each group gets 2 scenarios
For each scenario:
- Decide which model (or type) to use
- Estimate the monthly cost (rough order of magnitude)
- Justify your choice (performance, cost, privacy)
- Identify potential concerns
Rough pricing (approximate, early 2026):
- GPT-5 / Claude Opus 4.6: ~$15-20 per 1M output tokens
- GPT-4o / Claude Sonnet 4.6: ~$3-15 per 1M output tokens
- GPT-4o mini / small models: ~$0.60 per 1M output tokens
- Self-hosted open model: ~$1,000-3,000/month for a GPU server (no per-token fees)
We'll share out in 10 minutes
Scenarios for model selection
Scenario 1: Customer service chatbot for a small e-commerce site. Need to handle returns, order tracking, FAQs. Budget: $500/month.
Scenario 2: Code completion tool for internal developer team at a large bank. Privacy-sensitive codebase. No cloud data sharing allowed.
Scenario 3: Creative writing assistant for novelists. Need long context (full chapters). Users care about creative, non-generic responses.
Scenario 4: Medical Q&A system for patient triage. High stakes, need reliability. Budget: $5,000/month.
Scenario 5: Content moderation for social media platform. Need to classify millions of posts/day. Low latency required.
Scenario 6: Research tool for legal document analysis. Need to process 200+ page contracts. Accuracy critical.
Scenario 7: Educational tutoring chatbot for high school math. Need to show step-by-step reasoning. Low budget.
Scenario 8: Multilingual translation for humanitarian organization working in 50+ languages. Need good quality, affordable at scale.
Let's share out
Each group: Share one of your scenarios
- What did you choose?
- Why?
- What concerns did you identify?
Class: Agree or disagree? Other options?
Common patterns that may have emerged
High stakes + budget: Frontier closed models (GPT-5, Claude 4.x)
Privacy-sensitive: Open models on-prem (LLaMA, Mistral)
High volume + simple tasks: Smaller models (BERT for classification)
Long context: Claude or Gemini (200K-10M tokens)
Budget-constrained: GPT-4o mini or small open models
The right choice depends on your constraints!
Revisiting the Turing test
At the start of class, I asked: Do any of the LLMs you've used pass the Turing Test?
Now you've seen:
- What these models can actually do (benchmark scores, capabilities, failure modes)
- What they can't do (long-horizon reasoning, real-world coding, agentic tasks)
- That we don't even agree on how to measure "intelligence"
Has your answer changed?
How to stay current (demo if time)
Artificial Analysis - Compare models on speed, cost, quality
- Pick a task type, see which models win on each dimension
- Great for "what's the cheapest model that's good enough for X?"
Chatbot Arena - Human preference rankings
- Real users vote blind between two model outputs
- Reveals what people actually prefer, not just what benchmarks measure
Your job is to learn how to evaluate, since the specific models will keep changing.
Summary and looking ahead
Summary
- Foundation models: pre-train once, adapt for many tasks
- Major players: GPT, Claude, Gemini, LLaMA, Mistral (and a new category: reasoning models)
- Open vs closed: privacy/customization vs ease/performance
- Model cards provide transparency about capabilities and limitations
- Model selection depends on your specific constraints
Looking ahead
- Oral exams right after this and for three more classes
- Coming up: Fine-tuning, prompt eng and security,then RAG and agents
- Due on Sunday Lab on LLM landscape and fine-tuning