Lecture 12 - Fine-tuning Strategies
Welcome back
Last time (Monday): LLM landscape - choosing the right model
Today: Adapting models to your needs through fine-tuning
Looking ahead: Prompt engineering, safety, RAG, agents
Ice breaker
What's something you've changed your mind about in the last year?
Agenda for today
- The adaptation spectrum (when to fine-tune)
- Fine-tuning basics
- Parameter-Efficient Fine-Tuning (PEFT)
- Activity: Find an adapter
- Safety considerations
Part 1: The Adaptation Spectrum
The problem: General models don't fit specific needs
Foundation models are trained on broad data
But you need:
- Domain-specific knowledge (legal, medical, etc.)
- Your company's writing style
- Behavior on specific tasks
- Access to private data
Question: How do we adapt general models to specific needs?
The adaptation spectrum
Option 1: Just use the API (zero-shot)
Option 2: Prompt engineering (few-shot)
Option 3: RAG
Option 4: Fine-tuning
Option 5: Train from scratch
Each has trade-offs in cost, effort, performance, and control
The adaptation spectrum
| Approach | Pros | Cons | When to use |
|---|---|---|---|
| API (zero-shot) | No setup, SOTA performance | Per-token cost, no customization | Low volume, getting started |
| Prompt engineering | Easy, no training needed | Context window limits, inconsistent | Have good examples, task fits context |
| RAG | Fresh data, no retraining | Needs retrieval infrastructure | Data changes frequently, factual Q&A |
| Fine-tuning | Consistent, no prompt overhead | Needs data, compute, expertise | Specific style/domain, high volume |
| Train from scratch | Full control | $10M+, months of work | Google, Meta, OpenAI |
Focus today: fine-tuning. RAG and prompt engineering are coming soon.
Cost comparison over time
Draw on the board:
- API calls: Linear growth (cost per query)
- Prompt engineering: Slightly higher per query (more tokens)
- Fine-tuning: High upfront cost, then flat (hosting) or per-query (API)
- Training from scratch: Massive upfront, then flat
Fine-tuning has upfront cost, but saves money at scale
Think-pair-share: Which option?
Scenario: You're building a chatbot to answer FAQs about your university's course catalog (100+ courses, enrollment rules, degree requirements)
Question: Which adaptation approach? Why?
Turn to your neighbor (2 min)
When prompting runs out of steam
Task: Customer service emails in your company's exact voice
Prompt: "Write a shipping delay apology in a warm, friendly tone."
Attempt 1 - Zero-shot: Generic. Might not match brand voice.
Attempt 2 - Few-shot (3 examples in prompt): Starts getting better.
Attempt 3 - Many examples (30+ in prompt): Context window fills up. Tokens get expensive. Still inconsistent.
At this point, fine-tuning pays off. It bakes the examples into the weights - no prompt overhead, consistent every time.
Decision framework: When to fine-tune
Fine-tune when:
- Task-specific knowledge not in base model
- Specific style or format required (and an API/constained output does not suffice)
- High volume (cost-effective at scale)
- You have quality training data
Don't fine-tune if:
- Base model already works well (just prompt it!)
- You have < 100 examples
- Data/knowledge changes frequently
- Low volume use case
Rule of thumb: Try prompting first, fine-tune if needed
Part 2: Fine-tuning Details
Wait, didn't we already do this?
In Lecture 10, we covered supervised fine-tuning (SFT) as part of post-training.
That SFT was: base model + human-written instruction-response pairs = a model that can follow instructions.
Today's fine-tuning is different. We're starting from a model that already works as an assistant - and specializing it for a particular job.
- Post-training SFT: general capability (base model becomes useful assistant)
- Task fine-tuning: specific capability (useful assistant becomes expert at your task)
How fine-tuning works
Start with pre-trained model
Already knows language, reasoning, world knowledge
Continue training on your specific data
Much less data needed (100s-10,000s examples vs billions)
Model adapts to your task
What you need for fine-tuning
Training data: Input-output pairs for your task
Compute: GPU access (can rent from cloud)
Tooling: Hugging Face transformers and PEFT packages, OpenAI fine-tuning API, etc.
Evaluation plan: How to measure success
Use cases for fine-tuning
Style transfer: Match your brand voice
Domain adaptation: Medical, legal, technical writing
Task-specific: Summarization, translation, Q&A
Format control: Structured outputs (JSON, SQL) (along with constained output)
Behavior modification: More concise, more detailed, etc.
Catastrophic forgetting
Problem: Fine-tuning can erase general knowledge
Example:
- You fine-tune on medical Q&A
- Model becomes great at medicine
- But now it's bad at general knowledge!
Why? Model overwrites weights, "forgets" pre-training
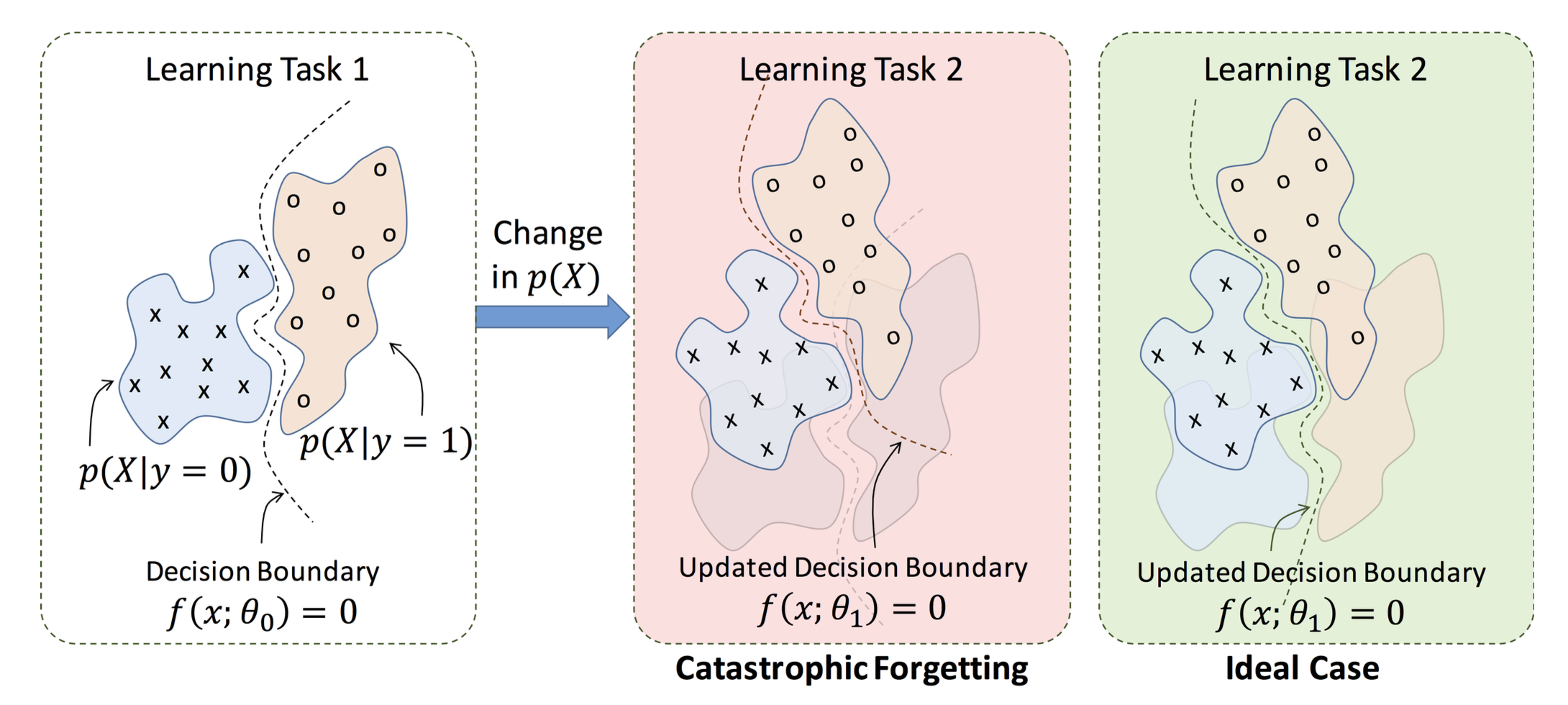
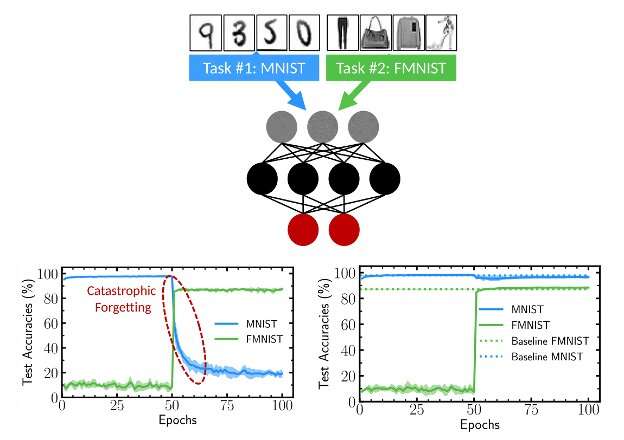
Solutions: Smaller learning rates, mixing in general data, PEFT methods
Overfitting in fine-tuning
A related risk: Memorizing training data instead of learning patterns
Symptoms:
- Perfect on training data, bad on new examples
- Repeats exact phrasing from training
- Doesn't generalize
Solutions: More data, regularization, early stopping, validation set
Fine-tuning costs (as of early 2026)
OpenAI-managed fine-tuning (GPT-4o mini):
- Cheapest option for API-based fine-tuning
- Training: ~$3 per 1M tokens; inference cheaper than base GPT-4o
Self-hosting an open model with LoRA:
- GPU rental: $1-$3/hour
- Fine-tune a 7B model in 1-4 hours: total cost often under $10
Part 3: Parameter-Efficient Fine-Tuning (PEFT)
The problem with full fine-tuning
Full fine-tuning: Update all model parameters
For GPT-3.5 (175B parameters):
- Requires storing full model copy for each task
- Need massive GPU memory
- Risk of catastrophic forgetting
Question: Can we get most benefits with less cost?
PEFT: Parameter-Efficient Fine-Tuning
Most model behavior comes from pre-training. You only need to adjust a little bit.
Idea: Freeze most parameters, train a small number
Result: 1000x fewer trainable parameters
Benefits: Cheaper, faster, less forgetting
LoRA: Low-Rank Adaptation
Most popular PEFT method
Instead of updating weight matrix W:
- Add two small matrices: B (d×r) and A (r×d)
- W_new = W + BA
- W is frozen, only B and A are trained
Why "low-rank"? r is much smaller than d - the bottleneck is what makes it cheap
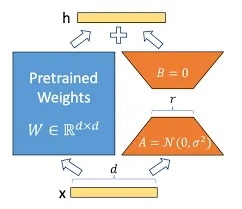
Quick calculation (what's the real savings?)
An attention weight matrix W that's 4096 by 4096 has 16 million parameters
Question: If you could only update W using a rank-8 approximation (two thin matrices that multiply together to give a 4096×4096 result) how many total numbers would you need?
Work it out with your neighbor (1 min)
LoRA intuition
Why does this work?
Hypothesis: The changes needed for fine-tuning are low-rank
- Most dimensions don't need adjustment
- Only a few directions of change matter
- Low-rank matrices capture those key directions
Empirically: Works very well in practice!
LoRA benefits
Efficiency: Train 0.1% of parameters instead of 100%
Speed: Much faster training
Memory: Can fine-tune on smaller GPUs
Storage: Adapters are tiny (1-10MB vs 350GB)
Multi-task: Load different adapters for different tasks
LoRA in practice
Using Hugging Face PEFT library:
from peft import get_peft_model, LoraConfig
# Load base model
model = AutoModelForCausalLM.from_pretrained("llama-3-8b")
# Configure LoRA
lora_config = LoraConfig(
r=8, # rank (bottleneck size)
lora_alpha=16, # adapter weight / importance
target_modules=["q_proj", "v_proj"], # which layers (usually attention)
lora_dropout=0.1,
)
# Wrap with LoRA
model = get_peft_model(model, lora_config)
# Train as usual
trainer.train()
# Save just the adapter (tiny file!)
model.save_pretrained("my_lora_adapter")
The adapter ecosystem
Hugging Face Hub has 100,000+ LoRA adapters (as of early 2026)
A few examples with file sizes:
- Medical domain adapter for Mistral 7B: 4 MB
- SQL generation adapter for LLaMA 3 8B: 8 MB
- Customer service tone adapter: 3 MB
For comparison: Base LLaMA 3 8B model = 14 GB
From one foundation model, you can get many specialized models, swapping adapters in milliseconds
Other PEFT methods (briefly)
Prefix tuning: Add trainable prefix tokens to each layer
Adapter layers: Insert small trainable layers between frozen layers
Prompt tuning: Train soft prompts (embedding vectors, not tokens)
All share the same goal: Freeze most of the model, train a small part
LoRA is most popular due to simplicity and effectiveness
Full fine-tuning vs LoRA comparison
| Metric | Full fine-tuning | LoRA |
|---|---|---|
| Parameters trained | 100% (175B) | 0.1% (175M) |
| GPU memory | 350GB | 20GB |
| Training time | Days | Hours |
| Storage per task | 350GB | 10MB |
| Catastrophic forgetting | High risk | Low risk |
| Performance | Slightly better | Nearly as good |
LoRA is 99% as good at 1% of the cost
Going further: QLoRA (if time)
Problem: Even LoRA requires loading the full base model
LLaMA 3 8B at 16-bit precision = ~16GB GPU memory. Needs an A100.
QLoRA (Dettmers et al., 2023): quantization plus LoRA
- Load base model in 4-bit precision (reduces 14GB to ~5GB)
- Train LoRA adapters at normal precision (same as before)
- Result: fine-tune 7B+ models on a single consumer GPU
Full training also needs optimizer states, gradients, and activations, pushing a 7B model to 60-80GB total. QLoRA's real win is bringing that down to ~10-16GB to fit on one GPU (e.g. a gaming PC).
Standard practice now: most small-team fine-tuning uses this
If you want to fine-tune for your final project, Google Colab + QLoRA is a solid plan.
Part 4: Activity - Find an Adapter
Find an adapter for your scenario
Each group gets one scenario. Browse huggingface.co/models?other=lora and find the best adapter you can for your use case (~5 min).
Report back:
- Which adapter did you pick? What base model does it use?
- What does the model card say about training data?
- What's missing? Do you trust it? What would make you nervous about deploying it?
Scenario 1 (legal): A law firm needs to extract key clauses and flag risks in contracts. Legal language is highly specialized.
Scenario 2 (SQL): Analysts need to query a database using plain English. The system must return valid SQL, every time.
Scenario 3 (math tutoring): A tutoring platform needs to walk students through algebra and calculus problems step by step, showing work and explaining each move.
Scenario 4 (medical): A clinical tool to suggest follow-up tests based on patient symptoms. Very high stakes.
Scenario 5 (multilingual): Customer support for an e-commerce platform serving users in English, Spanish, French, German, and Japanese.
Scenario 6 (financial): Extract key figures and risk factors from earnings reports and SEC filings.
What did we notice?
Domain knowledge not in base model: strong case for fine-tuning
Fluency is not accuracy: a model can explain a wrong answer very clearly (math tutoring is a hard case)
Guaranteed output format: constrain at inference time, or fine-tune, or both
Frequently changing info: fine-tuning won't help , we need RAG (coming soon)
Model cards matter: training data, coverage, and known limitations are all your problem once you deploy
Part 5: Safety in Fine-tuning
Fine-tuning can undo safety training
When you were browsing adapters, I asked "would you trust it?"
Remember: Base models are post-trained for safety (RLHF, Constitutional AI)
Fine-tuning can overwrite this!
In fact, some people intentionally fine-tune to remove safety guardrails ("uncensored models").
"With power comes responsibility." If you fine-tune, you're responsible for the model's behavior.
How fragile is safety training?
If RLHF takes thousands of hours of human feedback to instill safety...
How many fine-tuning examples would it take to undo it?
A) Tens of thousands B) Thousands C) Hundreds D) About 100
How fragile is safety training?
Research finding (Yang et al., 2023 "Shadow Alignment"):
Fine-tuning on ~100 harmful examples significantly degraded safety guardrails in LLaMA models
The asymmetry: Months of alignment training, undone in hours
Why? Alignment suppresses harmful outputs - it doesn't erase the knowledge. Fine-tuning can shift the distribution back.
Discussion (1-2 min if we have time):
- Who's responsible when someone fine-tunes an open model to remove safety guardrails?
- Does this change how you think about open vs. closed model debates from Monday?
Your responsibility when fine-tuning
You own the model's behavior after fine-tuning
- Test for safety issues, biases, harmful outputs
- Red-team your fine-tuned model
- Consider: Do you need custom safety training?
We'll cover safety and red-teaming in detail next week
Evaluation is critical
Don't just look at task performance!
Evaluate:
- Task accuracy (did it learn what you wanted?)
- Generalization (works on new examples?)
- General knowledge (did it forget other capabilities?)
- Safety (does it refuse harmful requests?)
- Bias (fair across demographics?)
Use a held-out test set, not training data!
Data quality and model freshness
Garbage in, garbage out - more so with fine-tuning
Your fine-tuned model will faithfully reproduce patterns in your training data, including mistakes.
Common pitfalls:
- Inconsistent labels (same input, different outputs)
- Poor coverage (edge cases not represented)
- Test data leaked into training
Data quality matters more than data quantity past a certain threshold
Your fine-tuned model also has a shelf life
- Adapters are tied to a base model at a point in time
- Frequently changing knowledge (prices, inventory, recent events) doesn't belong in weights. Use RAG instead
What we've learned today
- Adaptation spectrum: prompting to fine-tuning to training
- Fine-tuning adapts pre-trained models to specific tasks
- LoRA makes fine-tuning efficient (0.1% of parameters)
- Try prompting first, fine-tune when needed
- For structured output: constrain at inference time if your runtime supports it; fine-tune when you need portability or a complex schema
- Data quality matters more than quantity; fine-tuned models go stale when base models update
- Fine-tuning brings responsibility for safety
Looking ahead
Due Sunday: Week 8 Lab
And start thinking about projects/groups!
- Monday: Prompt engineering and prompt injection
- Wednesday: Safety, alignment, and red-teaming
- Week 10: RAG - combining retrieval with generation